Empecemos por la pregunta que te trajo hasta aquí, sin rodeos: sí, el web scraping es legal en España. Lo declaró el Tribunal Supremo en 2012, y la cosa no ha cambiado desde entonces. Pero —y este "pero" lo cambia absolutamente todo— solo es legal cuando respetas tres límites: los datos personales, los derechos de autor y los términos del sitio que rascas.
Ahí está el matiz que casi nadie te explica bien.
La mayoría de artículos que vas a encontrar sobre esto los han escrito o bufetes que quieren venderte una consulta, o competidores nuestros que apenas tocan la jurisprudencia española. Nosotros vamos a hacer algo distinto. Te vamos a contar qué dice la ley de verdad, qué sentencias marcaron el terreno, y dónde está exactamente la línea roja. Con casos reales. Con números. Y al final, cómo extraer datos sin dolores de cabeza legales.
Aviso rápido antes de seguir: este artículo es contenido informativo. No constituye asesoramiento jurídico personalizado. Si tu caso es delicado, consulta con un abogado especializado en protección de datos.
Video: Cómo hacer scraping de Google Maps a escala de un país
- ¿Es legal el scraping en España? La respuesta corta
- Qué es el web scraping (y por qué genera debate legal)
- El marco legal del scraping en España y la UE en 2026
- Datos públicos vs datos personales: la línea roja del RGPD
- Jurisprudencia: los casos que definieron la legalidad
- ¿Cuándo el scraping se vuelve ilegal? Las 5 líneas rojas
- Cómo hacer scraping legal en España: buenas prácticas 2026
- Scraping legal de datos B2B con Google Maps (caso Scrap.io)
- Preguntas frecuentes sobre la legalidad del scraping
¿Es legal el scraping en España? La respuesta corta
El web scraping, como técnica, es legal en España. Punto de partida. Lo confirmó la sentencia del Tribunal Supremo 572/2012, que dio la razón a una empresa que rascaba datos de vuelos de otra. Es legal hacer scraping de información pública de empresa. Lo que puede convertirse en ilegal es qué extraes y cómo lo usas: datos personales sin base legal, contenido protegido por copyright, o saturar el servidor de la web objetivo.
O sea: la herramienta no es el problema. El uso sí puede serlo.
¿Te suena a respuesta de abogado escurridizo? Lo entiendo. Pero es que la realidad es exactamente esa. Y a lo largo de esta guía vas a ver por qué la distinción entre dato público y dato personal es la que decide si duermes tranquilo o no.
Qué es el web scraping (y por qué genera debate legal)
El web scraping —o raspado web— es la extracción automatizada de información publicada en sitios web mediante un programa. En lugar de copiar datos a mano, un bot recorre las páginas y los recopila a escala: nombres de empresa, precios, teléfonos, direcciones. Es la versión industrial del copiar y pegar.
Si te preguntas qué es el web scraping en la práctica, piensa en las páginas amarillas. Antes alguien hojeaba el listín y apuntaba números uno a uno. Hoy un script hace lo mismo con miles de fichas en minutos. Misma información pública. Distinta velocidad.
¿Y por qué levanta tanto debate jurídico una técnica tan simple? Por la escala. Una persona copiando 50 fichas no molesta a nadie. Un bot extrayendo 500.000 ya es otra cosa.
Aquí va un dato que pone las cosas en perspectiva: cerca del 50% del tráfico de internet en 2024 lo movían bots, no personas (Datstrats, 2024). La mitad. Internet ya es, en buena medida, máquinas hablando con máquinas. Y el negocio detrás crece a lo bestia: el mercado global del web scraping pasó de 0,99 mil millones de dólares en 2025 a 1,17 mil millones en 2026, con un crecimiento anual del 18,5% (Research and Markets / Mordor, 2026). Las proyecciones lo llevan hasta 2,28 mil millones para 2030 (The Business Research Company, 2026).
No es un truco de hackers en sótanos oscuros. Es una industria. De hecho, el ecosistema de los llamados alternative data mueve ya 4,9 mil millones de dólares, y el 67% de los asesores de inversión en EE.UU. usan datos alternativos —muchos obtenidos por scraping— para tomar decisiones (industry reports, 2026). Cuando Wall Street lo usa, deja de ser marginal.
El marco legal del scraping en España y la UE en 2026
Vamos con la parte densa. Pero te prometo que la dejo masticable.
No existe una "ley del scraping". Esa es la primera trampa. Lo que regula el raspado web son cuatro normas distintas que casi nunca te explican juntas, y que se solapan según qué tipo de dato toques. Aquí están.
RGPD (Reglamento UE 2016/679). El gran protagonista. Solo se aplica cuando hay datos personales de por medio: nombre de una persona física, email personal, móvil particular. Si extraes datos de personas, necesitas una base legal (normalmente el interés legítimo en B2B). Si extraes precios o categorías de negocio, el RGPD ni asoma. Es la clave de todo, y volveremos a ella en la siguiente sección.
LOPDGDD (Ley Orgánica 3/2018). La adaptación española del RGPD. Mismas reglas, matices locales. Lo importante: refuerza que el consentimiento no es transferible y que la AEPD (la autoridad española de protección de datos) vigila el cumplimiento.
LSSI-CE (Ley 34/2002). Regula las comunicaciones comerciales electrónicas. Es la que entra en juego si después usas los datos extraídos para cold email. En B2B permite contactar si lo que ofreces guarda relación con la actividad del destinatario y le das opción de baja. Siempre.
Directiva (UE) 2019/790 sobre derechos de autor en el mercado único digital. Sus artículos 3 y 4 reconocen la minería de textos y datos (TDM) como una actividad legítima. Traducción: extraer y analizar grandes volúmenes de datos es legal por defecto, salvo que el titular del sitio se haya reservado expresamente ese derecho de forma legible por máquina. Este es el marco que más se cita cuando se habla de scraping para entrenar IA.
Cuatro normas. Cuatro capas. Y el web scraping legal vive en la intersección donde las respetas todas a la vez.
Para los que mandáis emails fuera de la UE, añade una quinta: en Estados Unidos juegan la CFAA (fraude informático) y la CPRA/CCPA (privacidad en California). Distinto país, misma lógica de fondo: datos públicos, sí; abuso, no.
¿Quieres extraer datos de empresa sin pelearte con cuatro normativas a la vez? Scrap.io trabaja exclusivamente con datos business públicos de Google Maps —el dato de menor riesgo legal—, es RGPD y CCPA compliant, y cada dato es trazable a su fuente. Prueba gratis 7 días, 100 leads.
Datos públicos vs datos personales: la línea roja del RGPD
Si te quedas con una sola idea de todo el artículo, que sea esta.
Que un dato esté visible NO significa que sea de uso libre. La AEPD lo dice sin rodeos: una web abierta a cualquiera no es una "fuente de acceso público" en el sentido legal. Que puedas verlo no implica que puedas recopilarlo y usarlo como te dé la gana.
Y esto choca con el sentido común de mucha gente. En un hilo de Reddit en r/webdev alguien lo planteaba así: "Veo muchas webs con info pública que igualmente ponen avisos prohibiendo el scraping… ¿eso es vinculante?". Buena pregunta. La respuesta corta es: depende de si lo que rascas son datos personales o no.
Aquí está la distinción que lo decide todo:
| ✅ Datos públicos / B2B (riesgo bajo) | ❌ Datos personales (RGPD se aplica) |
|---|---|
| Nombre de la empresa | Nombre de una persona física |
| Dirección del local | Email personal ([email protected]) |
| Teléfono fijo del negocio | Móvil particular |
| Web y categoría en Google Maps | Perfil personal de LinkedIn |
| Horarios, nota media, nº de reseñas | Cualquier dato sensible |
La columna de la izquierda es terreno seguro. Un dato de empresa —su ficha, su teléfono fijo, su categoría— tiene un tratamiento legal mucho más laxo que el dato de una persona. Por eso, cuando alguien busca montar una base de datos de empresas para prospección B2B, la recomendación es clarísima: quédate en la columna verde.
La columna de la derecha es donde la gente se mete en líos. El scraping de datos personales sin una base legal sólida es justo lo que multan las autoridades. Y lo del consentimiento tiene truco: que alguien publicara su email en una web no equivale a que te diera permiso para añadirlo a tu campaña. Son cosas distintas.
¿La regla práctica? Si el dato identifica a una empresa, adelante con cuidado. Si identifica a una persona concreta, enciende todas las alarmas del RGPD.
¿Y se pueden extraer datos públicos legalmente, entonces? Sí, siempre que sean datos de empresa y no de personas. Esa es, en una frase, toda la diferencia.
Jurisprudencia: los casos que definieron la legalidad
La teoría está muy bien. Pero lo que de verdad marca dónde está la línea son las sentencias. Y aquí hay cuatro casos que conviene conocer, porque cuentan toda la historia.
En 2012, Ryanair llevó a Atrápalo a los tribunales por scrapear sus vuelos. La aerolínea quería frenar a la agencia de viajes. ¿El resultado? El Supremo le dio la razón… a Atrápalo. La STS 572/2012, del 9 de octubre de 2012, declaró que extraer datos de vuelos públicos no era competencia desleal. Fue la sentencia fundacional del caso Ryanair Atrápalo scraping en España, y todavía se cita.
Luego llegó Europa a matizar. En 2015, el TJUE resolvió otro pleito de Ryanair, esta vez contra PR Aviation, dejando claro que los términos y condiciones de una web pueden ser vinculantes contractualmente aunque la base de datos no esté protegida. O sea: leer la letra pequeña importa.
Y después, los dos casos que enfriaron a más de uno.
En Estados Unidos, hiQ Labs vs LinkedIn (2017-2022) parecía una victoria del scraping: los tribunales confirmaron que rascar datos públicos no viola la ley de fraude informático. Pero hiQ acabó pagando 500.000 dólares a LinkedIn por incumplir el contrato de uso. Público sí. Saltarse los términos, caro.
Y en Francia, la CNIL puso la guinda. Multó a la empresa KASPR con 240.000 euros por recopilar datos personales de perfiles de LinkedIn sin base legal (CNIL, 2022). Datos personales, sin consentimiento, con fines comerciales. La combinación prohibida.
| Caso | Año | País | Resultado |
|---|---|---|---|
| Ryanair vs Atrápalo (STS 572/2012) | 2012 | 🇪🇸 España | 🟢 Scraping declarado legal |
| Ryanair vs PR Aviation | 2015 | 🇪🇺 UE (TJUE) | ⚖️ Los términos pueden ser vinculantes |
| hiQ Labs vs LinkedIn | 2022 | 🇺🇸 EE.UU. | 🟡 Público OK, pero breach (500.000 $) |
| CNIL vs KASPR | 2022 | 🇫🇷 Francia | 🔴 Multa 240.000 € (datos personales) |
¿Ves el patrón? Cuando el dato es público y de empresa, los tribunales tienden a proteger al que rasca. Cuando hay datos personales o se incumple un contrato, llega la sanción. La frontera no es el scraping. Es el tipo de dato.
No es casualidad, además, que las autoridades europeas de protección de datos publicaran una declaración conjunta sobre el data scraping fijando su posición oficial. El mensaje a las plataformas y a quienes extraen: los datos personales públicos siguen siendo datos personales.
¿Cuándo el scraping se vuelve ilegal? Las 5 líneas rojas
El scraping no te mete en problemas por extraer datos. Te mete en problemas por cómo y para qué los extraes. Y aquí están las cinco líneas que no debes cruzar nunca:
- Extraer datos personales sin base legal (RGPD). Emails personales, móviles, perfiles de personas físicas sin interés legítimo ni consentimiento. Es la línea roja número uno, y la más multada.
- Vulnerar derechos de autor. Copiar contenido protegido —textos, fotos, bases de datos creativas— y republicarlo o revenderlo. La Directiva 2019/790 protege la minería de datos, no el plagio.
- Competencia desleal. Usar los datos rascados para hacer un calco de la web original o parasitar su esfuerzo comercial.
- Saturar el servidor (DDoS involuntario). Un bot mal hecho que machaca la web objetivo con miles de peticiones por segundo puede tumbarla. Eso ya no es scraping; es un ataque, y es delito.
- Eludir logins o muros de pago. Si para acceder al dato hay que registrarse, aceptar términos o pagar, saltárselo con un bot cruza la frontera. El dato deja de ser "público".
Fíjate en algo. Ninguna de estas cinco líneas tiene que ver con la extracción en sí. Todas tienen que ver con el respeto: a las personas, a la propiedad, al servidor ajeno. Un usuario lo resumía en Quora en español mejor que muchos manuales: "El scraping en sí no es ilegal; lo que puede serlo es lo que extraes y cómo lo usas." Exacto.
Y ojo con la matización que circula en foros como respuesta a la pregunta de si es ilegal hacer scraping de una web. En las PAA de Octoparse aparece a menudo esta idea: "No es legal si scrapeas información confidencial con fines de lucro." Es una simplificación, pero apunta bien: confidencial + lucro = problema. ¿Es legal vender bases de datos scrapeadas? Depende, otra vez, de si contienen datos personales y de cómo se obtuvieron. Si son datos de empresa públicos, hay margen. Si son personales sin base legal, ni lo intentes.
Cómo hacer scraping legal en España: buenas prácticas 2026
Bien. Ya sabes dónde están las líneas rojas. Ahora, ¿cómo se hace el scraping legal en la práctica, sin volverte paranoico? Aquí van las buenas prácticas que de verdad importan.
Prioriza datos de empresa, no de personas. Es la decisión que más riesgo elimina de golpe. Una ficha de Google Maps —nombre del negocio, dirección, teléfono fijo, web— es el dato de menor exposición legal que existe. Quédate ahí siempre que puedas.
Respeta el robots.txt y los términos. No es siempre vinculante, pero ignorarlo a lo bestia es buscarte problemas. Y no fuerces accesos detrás de logins.
No machaques el servidor. Limita la frecuencia de peticiones. Un scraper casero mal calibrado puede provocar ese "DDoS involuntario" del que hablábamos. Las herramientas serias gestionan esto por ti.
Documenta el origen de cada dato y ofrece opt-out. Si luego haces cold email, la LSSI-CE y el RGPD en el email marketing B2B en España te obligan a identificarte y a dar una baja fácil. En cada envío. Sin excepciones.
Usa herramientas que ya cumplan por ti. Aquí va una opinión honesta: montar tu propio scraper desde cero, en 2026, para prospección B2B, es perder el tiempo. Te pasas más horas parcheando código y gestionando la legalidad que usando los datos. Si quieres comparar opciones, mira nuestra guía de herramientas Google Maps scraper y la guía de cold email para la parte de contacto.
Lo decimos por experiencia: hemos visto a más de un cliente llegar quemado de mantener su propio bot. Lo construyeron, funcionó dos meses, la web objetivo cambió el HTML, y a empezar de nuevo. Sumando el riesgo legal de no saber bien qué estaban extrayendo. En fin, un dolor de cabeza evitable.
Scraping legal de datos B2B con Google Maps (caso Scrap.io)
Llegamos a lo concreto. ¿Es legal scrapear Google Maps? Sí, y es probablemente el caso más limpio de todos. Las fichas de empresa en Google Maps son datos business públicos: nombre, dirección, teléfono, web, categoría, horarios. La columna verde de la tabla de antes, entera.
Esto es justo lo que hace Scrap.io, y por eso encaja tan bien con todo lo que llevamos visto. La plataforma extrae solo fichas de empresa de Google Maps —nunca datos personales sensibles—, con 225.676.406 establecimientos indexados en 195 países (Scrap.io, 2026). Cada dato es trazable a su fuente, y la plataforma es RGPD y CCPA compliant.
¿Por qué es la opción de menor riesgo? Tres razones, rápidas.
Una: solo datos públicos de empresa, el dato de menor riesgo legal que existe. Dos: extracción sin código y a escala país en dos clics, lo que evita ese DDoS involuntario de los scrapers caseros mal hechos. Tres: filtras antes de extraer, así que solo trabajas con contactos útiles y en tiempo real.
Mira la interfaz. Eliges qué buscas y dónde:
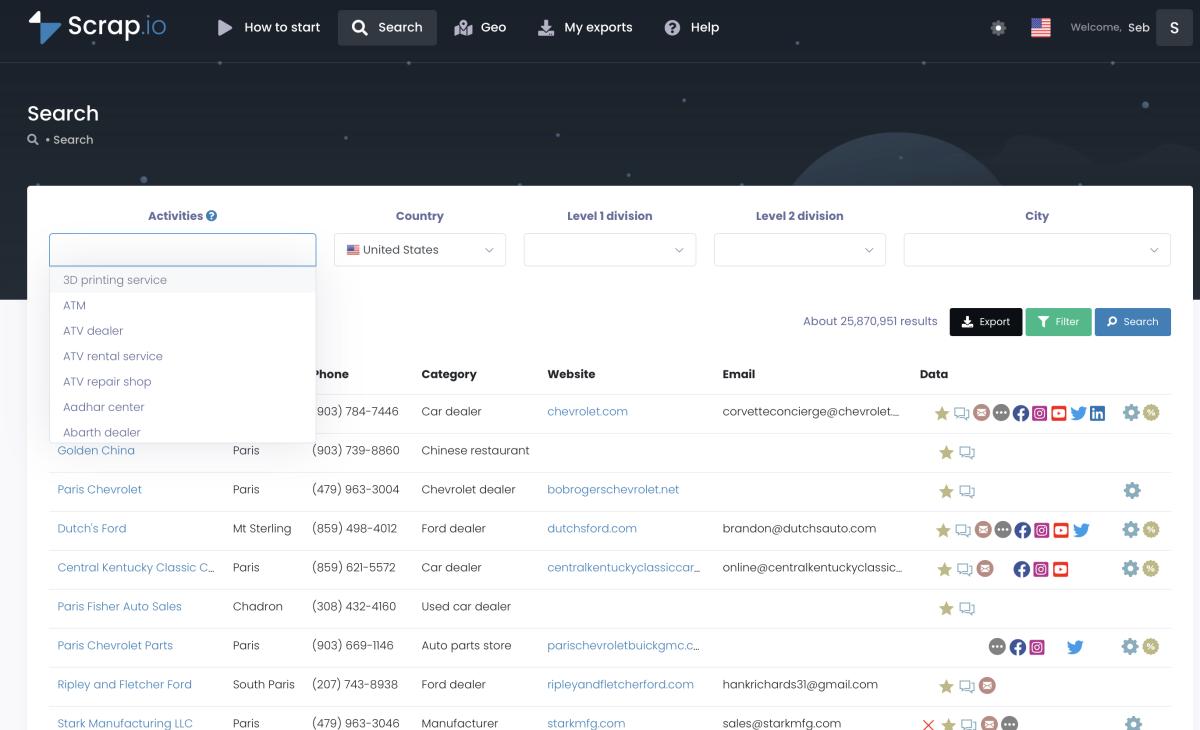
Y antes de gastar un solo crédito, aplicas filtros para quedarte solo con lo que te sirve —con email, con web, con una nota mínima:
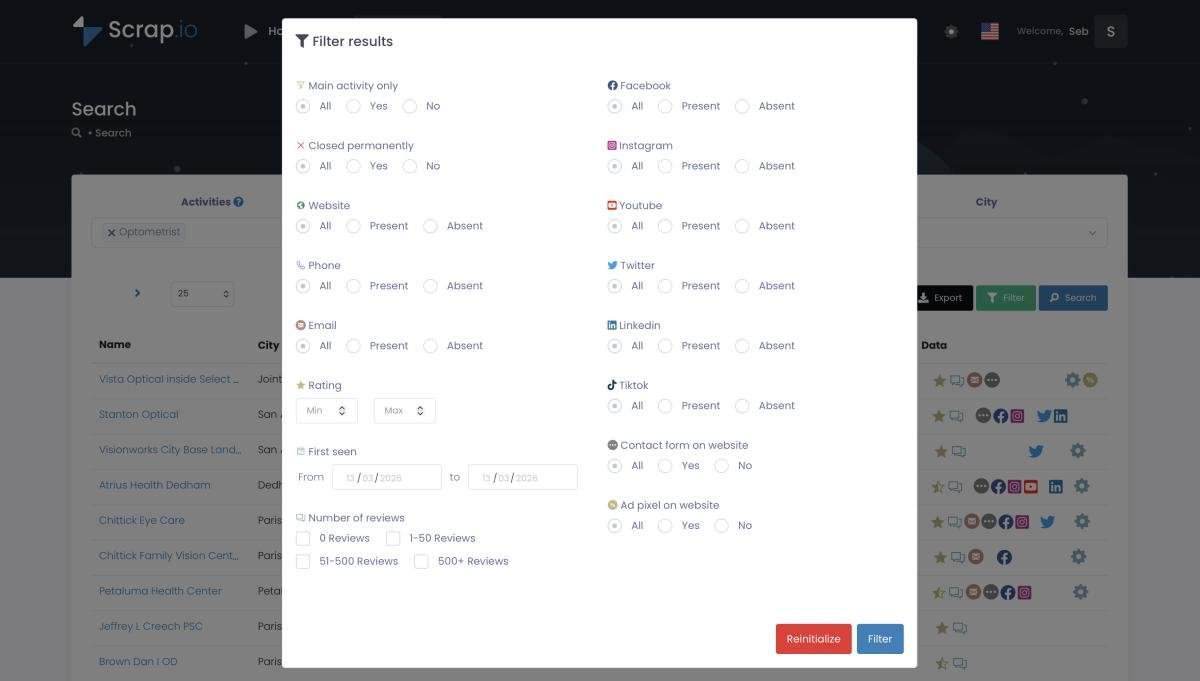
Y con la función GeoSearch dibujas tu zona —un radio o un polígono— sobre el mapa, para extraer datos de empresa de un área concreta:
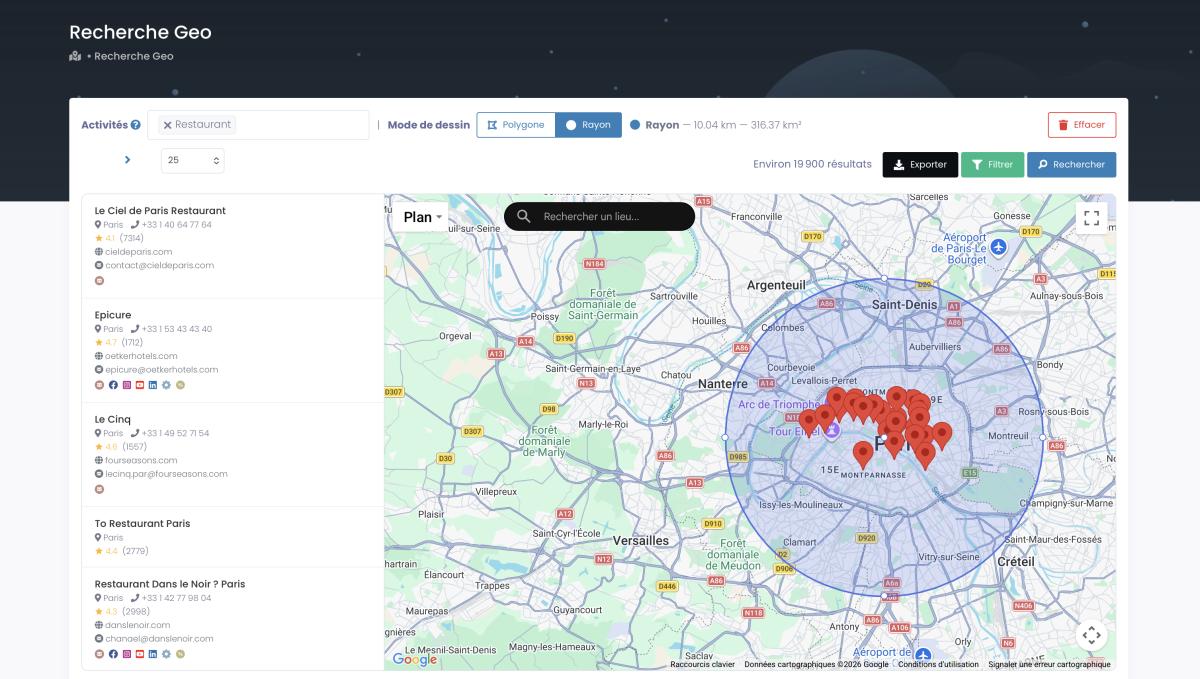
Si quieres el paso a paso completo, aquí tienes la guía de cómo extraer datos de Google Maps. Y si lo que buscas es montar un sistema de generación de leads B2B en España, ahí lo explicamos a fondo.
Video: Cómo crear listas de prospección en dos clics desde Google Maps con Scrap.io
Prueba Scrap.io gratis 7 días (100 leads): extrae datos de empresa de Google Maps —el dato de menor riesgo legal—, RGPD y CCPA compliant, sin código y a escala de un país entero. Empieza aquí.
Preguntas frecuentes sobre la legalidad del scraping
¿Es legal el web scraping en España?
Sí, como técnica es legal (STS 572/2012, caso Ryanair vs Atrápalo). Lo que puede ser ilegal es el uso: extraer datos personales sin base legal, vulnerar copyright, saltarse términos contractuales o saturar servidores. El web scraping legal de datos públicos de empresa está consolidado por la jurisprudencia española.
¿Qué dice el RGPD sobre el scraping?
El RGPD solo se aplica cuando hay datos personales de por medio, y entonces exige una base legal (como el interés legítimo en B2B). No afecta a los datos de empresa publicados ni a la información no personal —precios, productos, categorías—. Por eso scraping y RGPD conviven sin problema cuando trabajas solo con datos business públicos.
¿Es legal scrapear datos de Google Maps?
Sí. Las fichas de empresa de Google Maps son datos públicos: nombre, dirección, teléfono, web y categoría. Es legal scrapear Google Maps mientras te quedes en esos datos de negocio. Scrap.io extrae exactamente eso, y es RGPD y CCPA compliant.
¿Cuándo se considera ilegal el scraping?
Cuando se cruza alguna de las cinco líneas rojas: extraer datos personales sin base legal, vulnerar derechos de autor o propiedad intelectual, incurrir en competencia desleal, saturar el servidor objetivo (DDoS), o eludir logins y muros de pago. Cuándo es ilegal el web scraping depende del uso, no de la técnica.
¿Es legal el scraping de LinkedIn?
Zona gris. Los perfiles son públicos, pero contienen datos personales y la plataforma prohíbe el scraping en sus términos. La CNIL multó a KASPR con 240.000 € justo por esto. Si te preguntas si es legal el scraping de LinkedIn, la respuesta prudente es: mejor no. Para prospección B2B, usa datos de empresa de Google Maps, que tienen un riesgo legal mucho menor.
El scraping legal no es complicado: fuentes públicas de empresa + herramientas que respetan la ley. Si quieres extraer datos B2B sin zonas grises, empieza con Scrap.io gratis 7 días, 100 leads. Datos de Google Maps, RGPD compliant, trazables a su fuente. Y si después montas tus campañas, aquí tienes la guía de generación de leads B2B en España.
Disclaimer: este contenido es informativo y no constituye asesoramiento jurídico personalizado. La normativa y la jurisprudencia evolucionan; para decisiones concretas, consulta a un profesional del derecho.
Fuentes externas: EUR-Lex — Directiva (UE) 2019/790 · AEPD · vLex — STS 572/2012 (Ryanair vs Atrápalo) · PwC — Declaración de autoridades sobre data scraping · CNIL — Decisión KASPR · Octoparse · Reddit r/webdev
Ready to generate leads from Google Maps?
Try Scrap.io for free for 7 days.