📋 In Questa Guida
- Come Funziona il Web Scraping (Spiegazione Semplice)
- A Cosa Serve il Web Scraping: 6 Casi d'Uso Concreti
- I Migliori Strumenti di Web Scraping nel 2026
- Web Scraping con Python: Tutorial Base
- Esempi Reali: Chi Usa il Web Scraping (e con Quali Risultati)
- Il Web Scraping è Legale in Italia? Cosa Dice la Legge
- FAQ
Un dato che mi ha colpito: il 10,2% di tutto il traffico web mondiale proviene da scraper automatizzati (F5 Labs, 2026). Uno su dieci. E il mercato globale del web scraping? Partito da 1,03 miliardi di dollari, raggiungerà i 2 miliardi entro il 2030 con un tasso di crescita annuo del 14,2% (Mordor Intelligence, 2025). Insomma, non stiamo parlando di una nicchia per smanettoni.
Eppure — e questo mi stupisce sempre — la maggior parte delle guide italiane sul web scraping si ferma alla definizione da manuale. "È una tecnica per estrarre dati." Grazie, molto utile. Ma come funziona davvero? Serve saper programmare? È legale in Italia? E soprattutto: può servire al mio business o è roba per chi ha un team di sviluppatori?
Partiamo dalla base. Il web scraping (il termine viene dall'inglese "to scrape" — scraping significato: raschiare, grattare) è una tecnica automatizzata che usa software per estrarre dati strutturati da pagine web. Li prende e li converte in formati che puoi usare: CSV, JSON, Excel, database. Nel 2026 è diventato uno strumento chiave per lead generation, monitoraggio prezzi e analisi di mercato. Questo è il web scraping significato reale, al di là della traduzione letterale.
E no, non serve più essere sviluppatori. Questo è il punto che cambia tutto. Oggi un titolare di PMI a Bergamo, un freelance a Napoli o un'agenzia marketing a Roma possono estrarre dati dal web senza scrivere una singola riga di codice. Con risultati che fino a tre anni fa richiedevano un programmatore dedicato.
Vediamo come.
Come Funziona il Web Scraping (Spiegazione Semplice)
Il web scraping è una tecnica automatizzata che invia una richiesta a un sito web, ne legge il codice HTML e ne estrae le informazioni utili, salvandole in un formato strutturato come CSV o Excel. Tre passaggi, in pratica. Nient'altro.
Il meccanismo è più semplice di quanto pensi.
Primo: la richiesta HTTP. Il software manda una richiesta a un sito web. Identica a quella che manda il tuo browser quando apri una pagina. Stessa identica cosa — solo che lo fa un programma al posto tuo.
Secondo: il parsing HTML. La pagina arriva. Il programma la legge, analizza il codice e identifica le informazioni che ti servono. Come un setaccio: passa tutto e trattiene solo quello che cerchi.
Terzo: l'estrazione. I dati vengono tirati fuori, ripuliti e salvati in un formato strutturato. Un CSV, un file Excel, un JSON. Pronti da usare, importare nel CRM, analizzare.
Fine. Seriamente, è tutto qui. La complessità sta negli strumenti e nei dettagli tecnici (proxies, CAPTCHA, rendering JavaScript), ma il concetto di base è questo. Se vuoi la definizione accademica completa, c'è anche la voce Wikipedia sul web scraping — ma onestamente quello che ti ho scritto sopra basta e avanza.
Differenza tra Web Scraping e Web Crawling
Confusione classica. Tantissime persone usano questi due termini come sinonimi, ma sono cose diverse.
| Web Scraping | Web Crawling | |
|---|---|---|
| Obiettivo | Estrarre dati specifici | Indicizzare pagine web |
| Portata | Pagine mirate | L'intero web |
| Output | Dati strutturati (CSV, JSON) | Indice di URL |
| Esempio | Estrarre prezzi da un e-commerce | Googlebot che scansiona il web |
Per semplificare: il crawling esplora (Googlebot è un crawler), lo scraping raccoglie (un tool che estrae tutti i ristoranti di Milano da Google Maps è uno scraper). Quando qualcuno ti dice "ho fatto scraping del web" e intende che ha indicizzato migliaia di URL, tecnicamente sta sbagliando. Ma non diglielo, si offende.
Con il web scraping puoi estrarre di tutto: email, numeri di telefono, prezzi di prodotti, recensioni, coordinate GPS, profili social, tecnologie usate sui siti web. La lista continua.
A Cosa Serve il Web Scraping: 6 Casi d'Uso Concreti
La teoria è bella, ma parliamo di cose concrete. Come viene usato il web scraping nel 2026 da aziende vere?
1. Lead Generation B2B
Probabilmente il caso d'uso più diffuso — e per buon motivo. Il 91% dei marketer mette la lead generation al primo posto tra le priorità (Reach Marketing, 2025). E il 75% riporta un aumento delle conversioni quando la generazione di lead è automatizzata (Demandsage, 2025).
Prendi Marco. Ha un'agenzia web a Milano e i suoi clienti ideali sono ristoranti che non hanno un sito. Prima passava le serate su Google Maps, cliccando scheda per scheda, copiando numeri di telefono su un foglio Excel. Un lavoro da matti. E qui il dato che cambia la prospettiva: in Italia ci sono 179.557 ristoranti indicizzati su Google Maps, e 94.969 — circa il 53% — non hanno un sito web (dati Scrap.io, luglio 2026). Cinquantatré per cento. Per un'agenzia web è letteralmente una lista di prospect perfetti che aspetta solo di essere contattata.
Adesso Marco cosa fa? Sceglie "ristorante", seleziona "Lombardia", filtra per "sito web assente" e in due minuti ha un file con migliaia di contatti. Email, telefono, indirizzo, tutto. Il suo problema non è più trovare i lead — è avere abbastanza tempo per contattarli tutti.
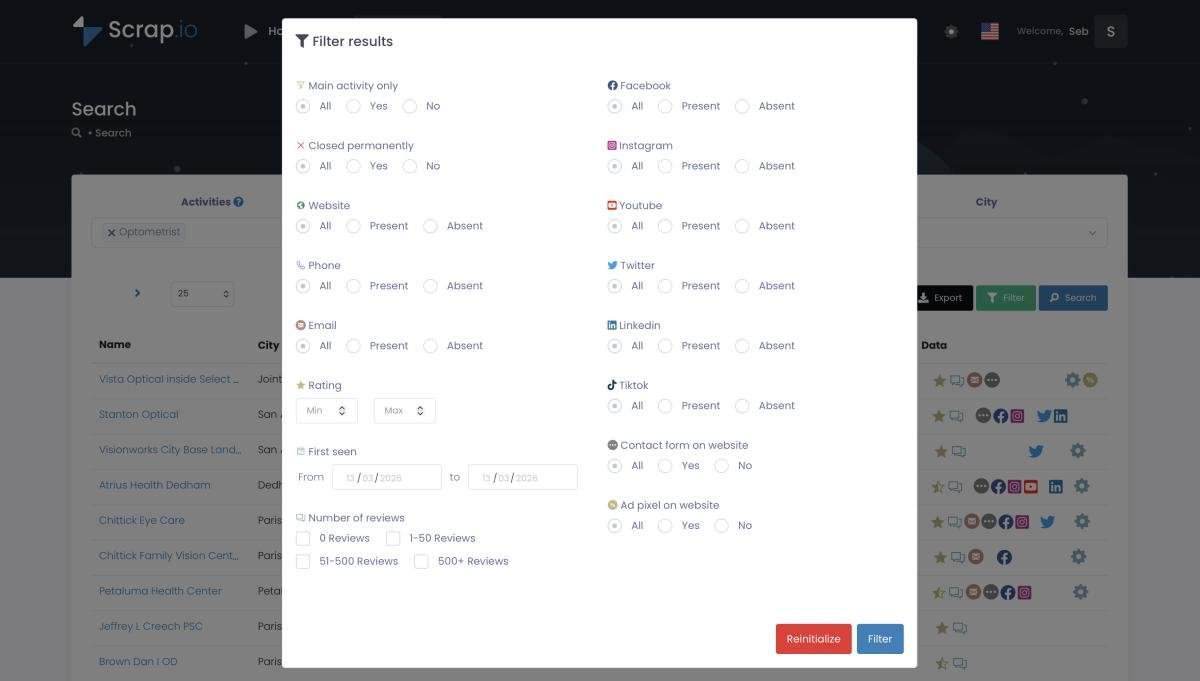
I filtri di Scrap.io: seleziona "sito web assente" prima di estrarre e paghi solo per i contatti che ti servono.
Scegli il tuo settore e testa con 100 lead gratuiti. Con oltre 225 milioni di stabilimenti indicizzati in 195 paesi e 4.000+ categorie, Scrap.io ti fa filtrare PRIMA di esportare — solo fiche con email, solo attività senza sito, solo quelle che vuoi tu. Prova gratuita di 7 giorni, 100 lead offerti.
2. Monitoraggio Prezzi E-commerce
Se vendi online e non monitori i prezzi della concorrenza, stai volando alla cieca. L'81% dei retailer USA usa già il price scraping automatizzato (Actowiz Solutions, 2025). Le aziende che adottano il dynamic pricing registrano aumenti del fatturato dal 5% al 25%, e McKinsey stima che la pricing analytics da sola può aumentare i profitti dal 2% al 7%.
Non è un'opzione. È diventata una necessità competitiva.
3. Ricerca di Mercato e Competitive Intelligence
Questa è sottovalutata. Un'agenzia di consulenza con cui ho parlato usa il web scraping per l'analisi di mercato e le schede Google Maps dei concorrenti dei propri clienti — quante recensioni hanno, che punteggio medio, se hanno un sito web aggiornato, quali tecnologie usano. In pratica costruiscono un quadro competitivo completo partendo da dati pubblici. Roba che manualmente richiederebbe settimane di lavoro e un foglio Excel da incubo. Con lo scraping? Ore. Poche ore.
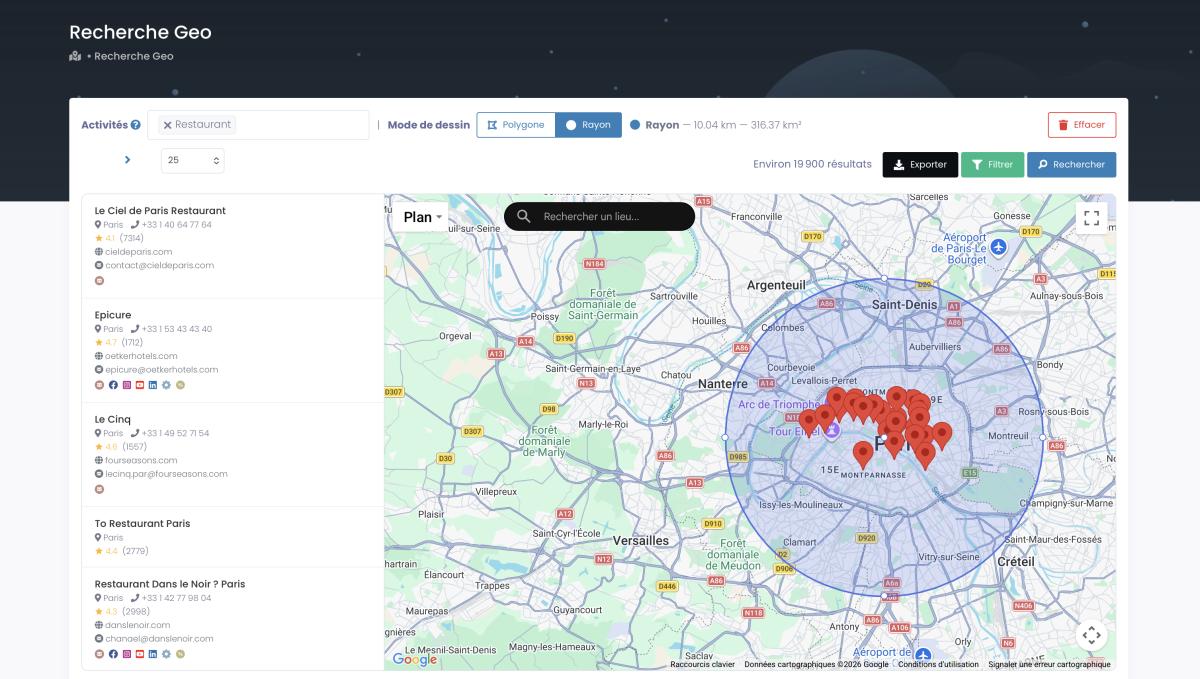
La ricerca geografica (radius o poligono) per mappare tutti i competitor di una zona.
Il web scraping ti permette di raccogliere trend di mercato, analisi del sentiment dei clienti, quote di mercato relative — tutto su una scala che il lavoro manuale non può raggiungere. Per le oltre 4 milioni di PMI italiane, questo tipo di intelligence competitiva era semplicemente inaccessibile fino a pochi anni fa.
4. Training AI e Machine Learning
Il 65% delle aziende usa il web scraping per alimentare progetti di AI e machine learning (BrowserCat, 2024). I modelli di intelligenza artificiale sono voraci di dati — ne servono tanti e di buona qualità. Il web è la fonte più grande che esista, e lo scraping è il modo più efficiente per raccoglierli su scala.
5. Monitoraggio Reputazione e Recensioni
Le recensioni influenzano le vendite molto più di quanto la maggior parte degli imprenditori realizzi. Un ristorante che passa da 3,5 a 4 stelle su Google Maps può vedere un aumento degli ordini del 5-9% — e un calo da 4 a 3,5 il contrario. Analizzare automaticamente le recensioni su Google Maps, TripAdvisor, Trustpilot permette di capire cosa i clienti pensano davvero. Non solo dei tuoi concorrenti — anche di te. Il web scraping ti dà la possibilità di aggregare centinaia o migliaia di recensioni, identificare pattern ricorrenti e agire prima che un problema diventi una crisi reputazionale.
6. Immobiliare e Recruiting
Annunci immobiliari, prezzi di mercato per zona, offerte di lavoro per settore. Sono tutti ambiti dove i dati cambiano continuamente, e dove avere informazioni aggiornate in tempo reale fa la differenza tra un affare chiuso e un'opportunità persa.
I Migliori Strumenti di Web Scraping nel 2026
Hai capito il concetto e i casi d'uso. La domanda adesso è pratica: con che strumenti si fa? Dipende molto da chi sei.
Strumenti con Codice (per Sviluppatori)
Python + BeautifulSoup — Il classico punto di partenza. Python domina con il 69,6% di adozione tra gli sviluppatori, e BeautifulSoup è perfetta per parsing HTML semplice su progetti piccoli e medi. Non è il tool più potente, ma la curva di apprendimento è gentile.
Scrapy — Quando BeautifulSoup non basta. Framework open source pensato per lo scraping a grande scala: migliaia di pagine, pipeline di dati complesse, gestione asincrona. Più ripido da imparare, ma molto più potente.
Selenium / Playwright — Per quei siti che caricano tutto con JavaScript e dove il codice sorgente è praticamente vuoto finché non lo renderizzi. Simulano un browser reale, il che risolve il problema ma aggiunge complessità e lentezza.
Strumenti No-Code (per Non-Programmatori)
Ed è qui che la partita si fa interessante per chi non scrive codice. I migliori web scraping tool senza codice, in breve:
- Octoparse — Interfaccia drag-and-drop, zero programmazione. Per chi vuole iniziare senza mal di testa tecnici, funziona. Non è il più flessibile, ma fa il suo lavoro.
- Apify — Piattaforma cloud con un marketplace di scraper già pronti. Cerchi quello che ti serve, lo configuri e parti. Utile soprattutto se hai bisogno di qualcosa di specifico che qualcun altro ha già costruito.
- Web Scraper (estensione Chrome) — Gratuita e semplice, ideale per chi ha bisogno di piccoli volumi. Se cerchi un strumento di web scraping gratis senza troppa complessità, questa è un'opzione decente per iniziare.
Scrap.io — E qui devo essere specifico perché è diverso dagli altri. Scrap.io non è uno scraper generico: è uno scraper per Google Maps specializzato nell'estrazione di dati aziendali. Scegli la categoria (tra più di 4.000 disponibili), scegli la zona — una città, una regione, o un intero paese — e lui estrae tutto. In due clic, senza codice. Con oltre 225 milioni di stabilimenti indicizzati in 195 paesi, la copertura è enorme. E i dati sono freschi: non un database statico scrapato sei mesi fa, ma estrazione in tempo reale a ogni export.
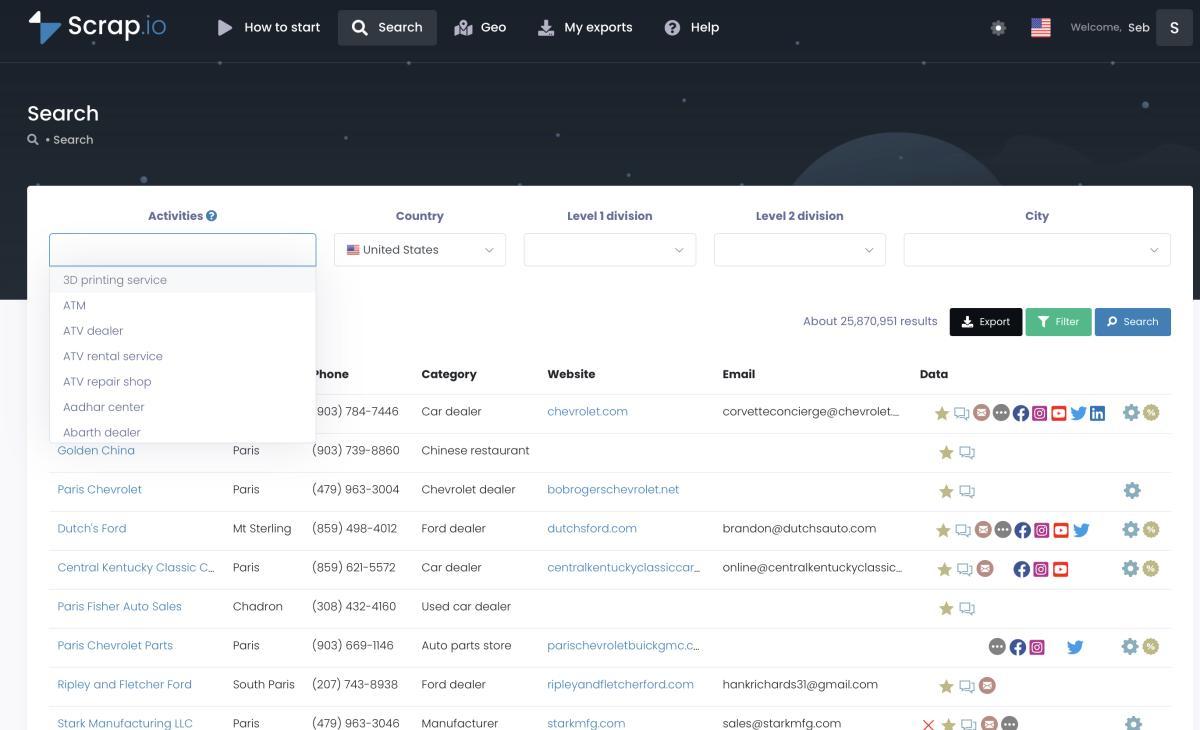
La ricerca di Scrap.io: categoria + zona, e il conteggio dei risultati è gratuito prima ancora di esportare.
Vuoi vederlo in azione? Ecco una demo (in inglese) che mostra come estrarre tutte le aziende di un territorio in un clic, senza nemmeno specificare la categoria.
Video (in inglese): estrarre tutte le attività di una zona in un clic, senza categoria.
API di Web Scraping
Le web scraping API sono la strada per chi ha bisogno di integrazione diretta nei propri sistemi — un CRM, una piattaforma di marketing automation, un'app custom.
Scrap.io mette a disposizione una API REST completa con queste caratteristiche:
- Limite di richieste: 300 richieste al minuto
- Autenticazione: Bearer token
- Formato: JSON per tutte le richieste e risposte
- Endpoint base:
https://scrap.io/api/v2/
L'API è inclusa in tutti i piani. Questo la rende ideale per automatizzare lo scraping con Make.com (la pagina è in francese/inglese — non esiste ancora una versione italiana) o con qualsiasi altra piattaforma di automazione che supporti chiamate REST. E se lavori con l'AI, c'è pure un connettore MCP ufficiale per pilotare tutto in linguaggio naturale da Claude, ChatGPT o Gemini.
Web Scraping con Python: Tutorial Base
Per chi cercava "web scraping python tutorial" in italiano — eccoci. Non è difficile come sembra. Quello che segue è un esempio base con BeautifulSoup che chiunque conosca un po' Python può replicare in mezz'ora.
# Installare le librerie necessarie
# pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
# 1. Inviare la richiesta HTTP
url = "https://esempio.com/pagina"
response = requests.get(url)
# 2. Parsing dell'HTML
soup = BeautifulSoup(response.text, "html.parser")
# 3. Estrarre i dati desiderati
titoli = soup.find_all("h2")
for titolo in titoli:
print(titolo.text)
Quattro passaggi. Installi, invii la richiesta, parsi, estrai. Un principiante ci mette meno di 30 minuti per far girare il primo script e vedere i primi web scraping esempi funzionanti.
Però devo essere onesto sui limiti. Appena vai oltre lo scraping basico, Python diventa complicato velocemente. Gestione dei proxies (perché i siti ti bloccano l'IP), CAPTCHA da risolvere, pagine che renderizzano contenuto con JavaScript, rate limiting da rispettare per non farsi bannare. Per progetti seri, queste complessità si sommano e il codice diventa un mostro da mantenere.
C'è un pattern che si ripete sempre, del resto. Su Reddit, nel subreddit r/webscraping, un utente riassumeva la cosa così: "Ho passato tre settimane a costruire uno scraper Python perfetto. Poi il sito ha cambiato layout e ho dovuto rifare metà del codice. Alla fine ho pagato per un servizio pronto e ho recuperato la mia vita." (fonte: Reddit r/webscraping). Non l'ho inventato io — è il tipico ciclo del "me lo faccio da solo".
Se non vuoi programmare — o se programmare non è il miglior uso del tuo tempo — strumenti no-code come Scrap.io o Octoparse danno risultati equivalenti con un decimo dello sforzo. È una questione di costi-opportunità, non di capacità tecnica.
Esempi Reali: Chi Usa il Web Scraping (e con Quali Risultati)
Basta parlare in astratto. Quello che manca in quasi tutte le guide italiane sul web scraping sono gli esempi concreti con numeri veri. Eccone quattro documentati.
Esempio 1 — itrinity (Portfolio SaaS)
itrinity gestisce un portfolio di prodotti SaaS e fa outreach verso affiliati YouTube. Il loro problema? Il processo era completamente manuale. Tra CAPTCHA, blocchi IP e copia-incolla, il team riusciva a mandare dieci email al giorno. Dieci. È come provare a svuotare il mare con un secchiello.
Hanno implementato uno scraper Apify per estrarre automaticamente i contatti dai canali YouTube, con validazione email integrata. Risultato: da 10 email al giorno a 400 a settimana. E 40 ore di lavoro manuale risparmiate ogni mese. Non è un miglioramento incrementale — è un cambio di scala.
Esempio 2 — Let's Fearlessly Grow (Agenzia Lead Gen, UK)
Agenzia B2B inglese che usa Clay AI per le campagne. Erano bloccati da Apollo.io: limitazioni, costi crescenti, dati non sempre aggiornati. Hanno integrato Apify con Clay per automatizzare lo scraping da fonti multiple.
Oggi generano oltre 2.500 email al giorno per ogni cliente. Hanno sostituito completamente le sottoscrizioni a database tradizionali. Questo è web scraping per email marketing B2B nella versione più concreta che esista.
Esempio 3 — Skuuudle (Pricing Intelligence E-commerce)
Skuuudle fa price scraping per retailer grandi — parliamo di Boots, Decathlon, aziende di quelle dimensioni. I numeri qui sono impressionanti: ROI dal 10x al 100x per i clienti. Per dare un'idea concreta: un'azienda con 500 milioni di dollari di fatturato spende 50-100 mila dollari l'anno per il servizio e recupera 2,5 milioni di dollari solo ottimizzando i prezzi dell'1%.
Cinquantamila investiti. Due milioni e mezzo di ritorno. I numeri non hanno bisogno di commento.
Esempio 4 — Dato Deloitte
Deloitte — una delle Big Four della consulenza, non un blog qualsiasi — ha documentato che il data-driven price management genera una crescita del ROI dal 200% al 350% in 12 mesi. Non è un'ipotesi. È un risultato misurato su aziende reali.
Vuoi provare qualcosa di simile? Inizia con 100 lead gratuiti. Su Scrap.io scegli il tuo settore e testa la qualità dei dati in tempo reale — email, telefono, social, filtrati prima dell'export. Se i contatti non sono buoni, non hai perso niente. Prova gratuita di 7 giorni.
Il Web Scraping è Legale in Italia? Cosa Dice la Legge
Il web scraping non è di per sé illegale in Italia: raccogliere dati pubblici è consentito. I problemi nascono quando si trattano dati personali senza una base giuridica valida, o si violano il GDPR e i Termini di Servizio. La risposta breve, quindi, è: dipende da cosa raccogli e come.
La domanda che tutti fanno, giustamente. E ci sono sfumature importanti, soprattutto con il GDPR e il Garante Privacy.
GDPR e Garante Privacy Italiano
Il Garante Privacy italiano ha aperto un'indagine formale sulle pratiche di web scraping. Il caso più clamoroso? La multa da 20 milioni di euro a Clearview AI per aver raccolto dati biometrici (riconoscimento facciale) senza alcun consenso. Quello è l'esempio perfetto di ciò che non devi fare.
E c'è di più. A maggio 2024 il Garante ha pubblicato un provvedimento specifico (n. 329 del 20 maggio 2024) intitolato "Web scraping ed intelligenza artificiale generativa", che aggiorna la posizione italiana alla luce dei nuovi sviluppi tecnologici — in particolare la raccolta massiva di dati per addestrare le AI. Se lavori in quest'ambito, leggilo. Davvero.
Quindi: attenzione, sì. Panico, no. Basta seguire le regole.
Best Practices per lo Scraping Legale
Cinque regole. Seguile e non avrai problemi.
- Rispetta il file robots.txt. È il primo segnale che un sito ti dà su cosa puoi e non puoi scrapare. Ignorarlo è il modo più rapido per avere problemi.
- Scrapa solo dati pubblicamente accessibili. Se l'informazione è visibile a chiunque senza login, sei su terreno solido.
- Evita i dati personali sensibili. Dati biometrici, sanitari, religiosi, politici — stanne alla larga a meno che tu non abbia una base giuridica solida (e un avvocato che ti conferma che ce l'hai).
- Controlla i Termini di Servizio. Alcuni siti vietano esplicitamente lo scraping. Non è sempre vincolante, ma saperlo prima ti evita sorprese.
- Non sovraccaricare i server. Limita la frequenza delle richieste. Nessuno apprezza un bombardamento di richieste HTTP — e un attacco DDoS involontario non è una bella difesa legale.
Il Caso hiQ vs LinkedIn
Un precedente internazionale che vale la pena conoscere. Negli Stati Uniti la giustizia ha confermato che lo scraping di dati pubblicamente accessibili su LinkedIn non viola il Computer Fraud and Abuse Act. Non è legge italiana, ovviamente. Ma è un segnale forte sulla direzione che sta prendendo la giurisprudenza globale riguardo allo scraping di dati pubblici.
Per le PMI italiane, piattaforme come Scrap.io semplificano la questione: raccolgono esclusivamente dati professionali che le aziende stesse hanno reso pubblici su Google Maps e sui propri siti web. Niente fonti opache, niente metodi discutibili. Dati pubblici, raccolti legalmente, tracciabili alla fonte. RGPD e CCPA compliant.
FAQ
Cosa si intende per web scraping?
Il web scraping è una tecnica automatizzata che usa software per estrarre dati strutturati da pagine web e convertirli in formati utilizzabili — CSV, JSON, database. Nel 2026 è diventato uno strumento diffuso ben oltre il mondo dello sviluppo: lo usano agenzie marketing, PMI, freelance e grandi aziende per lead generation, monitoraggio prezzi, ricerca di mercato e progetti di intelligenza artificiale.
Il web scraping è illegale in Italia?
No, non è intrinsecamente illegale. Però quando si trattano dati personali bisogna rispettare il GDPR e le indicazioni del Garante Privacy italiano. Lo scraping di dati pubblici per finalità commerciali è generalmente consentito, a patto di rispettare i Termini di Servizio dei siti e il file robots.txt. La multa a Clearview AI (20 milioni di euro) riguardava dati biometrici raccolti senza consenso — una situazione molto diversa dall'estrarre email aziendali da Google Maps.
Come fare web scraping senza codice?
Si usano strumenti no-code. Nella pratica: scegli una piattaforma come Scrap.io o Octoparse, imposti cosa vuoi estrarre (per Scrap.io: categoria + zona geografica), applichi i filtri e scarichi un file CSV o Excel. Zero programmazione. Con uno scraper per Google Maps come Scrap.io bastano letteralmente due clic per estrarre tutte le aziende di una città, una regione o un intero paese — con email, telefono e social già inclusi. È l'opzione più rapida per chi non è sviluppatore e vuole risultati subito.
Qual è la differenza tra web scraping e web crawling?
Lo scraping estrae dati specifici da pagine mirate e li salva in formato strutturato (CSV, JSON, Excel). Il crawling indicizza pagine web su larga scala — è quello che fa Googlebot. In breve: il crawling esplora, lo scraping raccoglie. Più sopra nell'articolo trovi una tabella comparativa dettagliata con obiettivi, portata, output ed esempi concreti per ciascuno.
Quali sono i migliori strumenti di web scraping gratuiti?
I tre che vale la pena provare: Web Scraper (estensione Chrome, buona per piccoli volumi), BeautifulSoup (libreria Python open source, richiede un minimo di programmazione) e Maps Connect di Scrap.io — estensione Chrome gratuita e senza limiti che mostra email e profili social direttamente sopra le schede Google Maps. Quest'ultima è particolarmente utile per chi fa prospecting B2B locale.
Il web scraping con Python è difficile?
Per le basi, no. Python è il linguaggio più accessibile per lo scraping grazie a librerie come BeautifulSoup e Scrapy. Un principiante che segue un tutorial può estrarre i primi dati in meno di mezz'ora. Dove le cose si complicano è con i progetti reali: gestione proxies, CAPTCHA, contenuti caricati con JavaScript, manutenzione del codice. Per chi non vuole programmare, alternative no-code come Scrap.io o Octoparse offrono risultati analoghi senza scrivere codice.
Conclusione
Il mercato del software di web scraping passerà da 718 milioni a 2,21 miliardi di dollari entro il 2033 secondo Straits Research, con un tasso di crescita annuo del 13,29%. Non è una moda. È infrastruttura digitale che sta diventando standard.
Sviluppatore Python che vuole automatizzare l'estrazione dati? Il web scraping ha una risposta. Imprenditore che deve trovare clienti su Google Maps senza perdere giornate intere? Ce l'ha lo stesso. I dati in tempo reale battono sempre i database obsoleti. Le soluzioni no-code hanno reso tutto accessibile. E il ritorno sull'investimento è documentato: dal 10x al 100x nel price monitoring, campagne di lead generation che scalano senza aggiungere personale, 200-350% di crescita ROI nel price management secondo Deloitte.
Poi certo, una volta estratti i contatti serve anche gestirli — un CRM per PMI ben popolato e una strategia di invio email massivo fatta a regola d'arte fanno il resto. Ma tutto parte da un dato fresco.
L'unica cosa che non puoi automatizzare è la decisione di iniziare.
Prova Scrap.io gratis per 7 giorni — 100 lead verificati. Oltre 225 milioni di aziende in 195 paesi, dati in tempo reale (mai un file vecchio di sei mesi), filtri prima dell'export così paghi solo i contatti utili. Scegli il tuo settore, scegli la tua zona, e vedi la differenza che fanno i dati aggiornati. Inizia ora →
Generate a list of restaurant with Scrap.io
