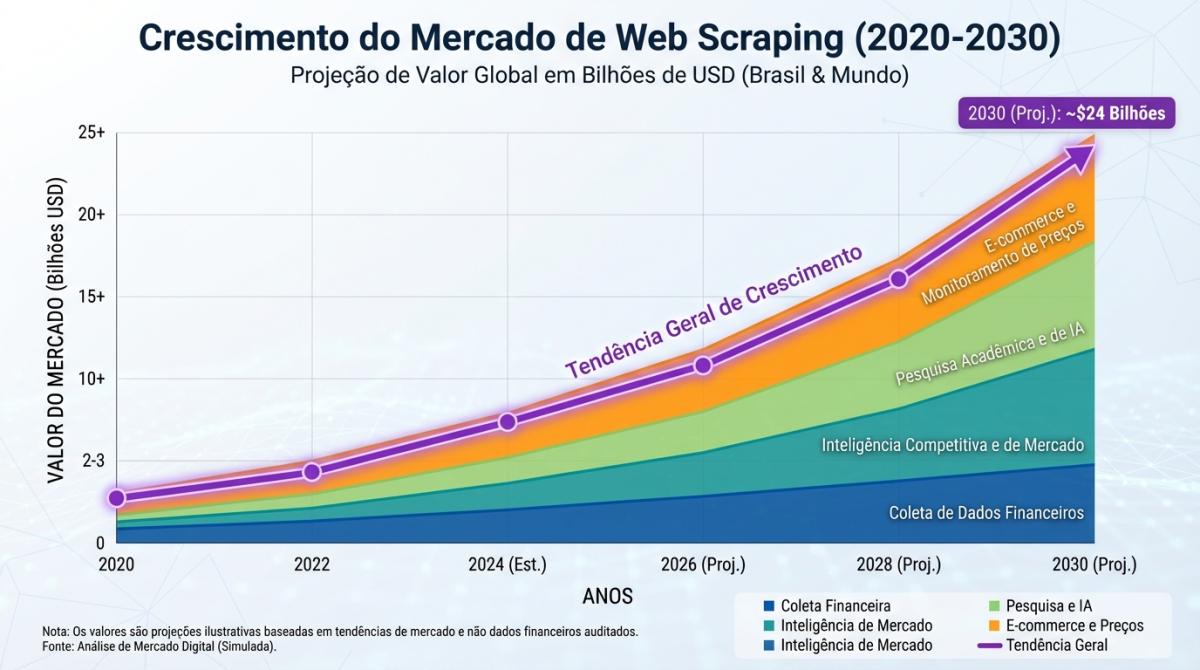
Em 2026, mais de 10% de todo o tráfego da internet é gerado por bots de coleta de dados — e o mercado de web scraping já ultrapassa US$ 1 bilhão. Se você ainda não sabe como essa tecnologia funciona, está perdendo uma das habilidades mais valiosas da economia digital.
Mas sabe o que é mais louco? A maioria das pessoas acha que web scraping é coisa de programador experiente, com linhas de código rodando em terminal preto. E não é bem assim. Hoje existe desde extensões gratuitas de Chrome até plataformas SaaS que fazem tudo em dois cliques. Literalmente dois cliques.
Neste guia vamos cobrir tudo — do básico até ferramentas reais, passando pela LGPD e exemplos concretos de empresas que já estão usando raspagem de dados pra crescer. Vamos lá?
O Que É Web Scraping? (Definição Simples)
Web scraping — também chamado de raspagem de dados ou raspagem da web — é o processo automatizado de extrair informações de sites da internet. Em vez de copiar e colar dados manualmente, um programa faz isso por você, de forma estruturada e em escala.
Em português, a tradução mais usada é raspagem de dados ou extração de dados da web. Mas no mercado brasileiro, o termo em inglês "web scraping" acabou prevalecendo mesmo.
Web Scraping vs Web Crawling: Qual a Diferença?
Muita gente confunde os dois. Aqui vai uma distinção rápida:
| Web Scraping | Web Crawling |
|---|---|
| Extrai dados específicos de páginas | Navega e indexa páginas da web |
| Objetivo: coletar informação estruturada | Objetivo: descobrir e mapear URLs |
| Exemplo: pegar emails de um diretório | Exemplo: o Googlebot indexando sites |
| Resultado: arquivo de dados (CSV, Excel) | Resultado: mapa de links e páginas |
Simplificando: o rastreador web é o que navega; o scraper é o que extrai. Na prática, muitas ferramentas fazem os dois.
Como Funciona o Web Scraping na Prática
O processo de extração de dados de sites segue basicamente quatro etapas:
- Requisição HTTP — o programa acessa a URL do site como se fosse um navegador
- Parsing do HTML — o código da página é analisado para identificar os elementos de interesse
- Extração — os dados específicos (nomes, emails, preços, etc.) são isolados
- Estruturação — as informações são organizadas e salvas em formato usável (CSV, JSON, Excel)
O componente que navega entre páginas é chamado de crawler; o que extrai dados específicos dentro de cada página é o scraper. Ferramentas profissionais combinam os dois num único fluxo automatizado.
Para Que Serve o Web Scraping? Aplicações Reais
Boa pergunta. Aqui estão os casos de uso mais comuns — e alguns vão te surpreender:
- Monitoramento de preços no e-commerce — acompanhar o que concorrentes cobram em tempo real
- Geração de leads B2B — encontrar empresas por segmento, região e dados de contato
- Pesquisa de mercado e inteligência competitiva — entender posicionamento e lacunas do mercado
- Monitoramento de avaliações e reputação — rastrear o que falam sobre marcas no Google e Reclame Aqui
- Recrutamento e dados de emprego — mapear vagas abertas e movimentos do mercado de trabalho
- Análise de sentimentos em redes sociais — extrair comentários para entender percepções do público
- Dados imobiliários e tendências — monitorar preços e lançamentos em determinadas regiões
Um caso concreto: imagine uma agência de marketing digital em São Paulo cujos clientes são pequenos restaurantes que precisam aparecer no Google. Como encontrar novos clientes toda semana? Com coleta automatizada de dados — mapeando todos os restaurantes de uma região, filtrando os que têm nota baixa ou nenhuma presença nas redes, e gerando uma lista de leads quentes automaticamente. É exatamente o que a Nodd Solutions faz com web scraper integrado ao Google Maps (mais sobre isso na seção de casos reais).
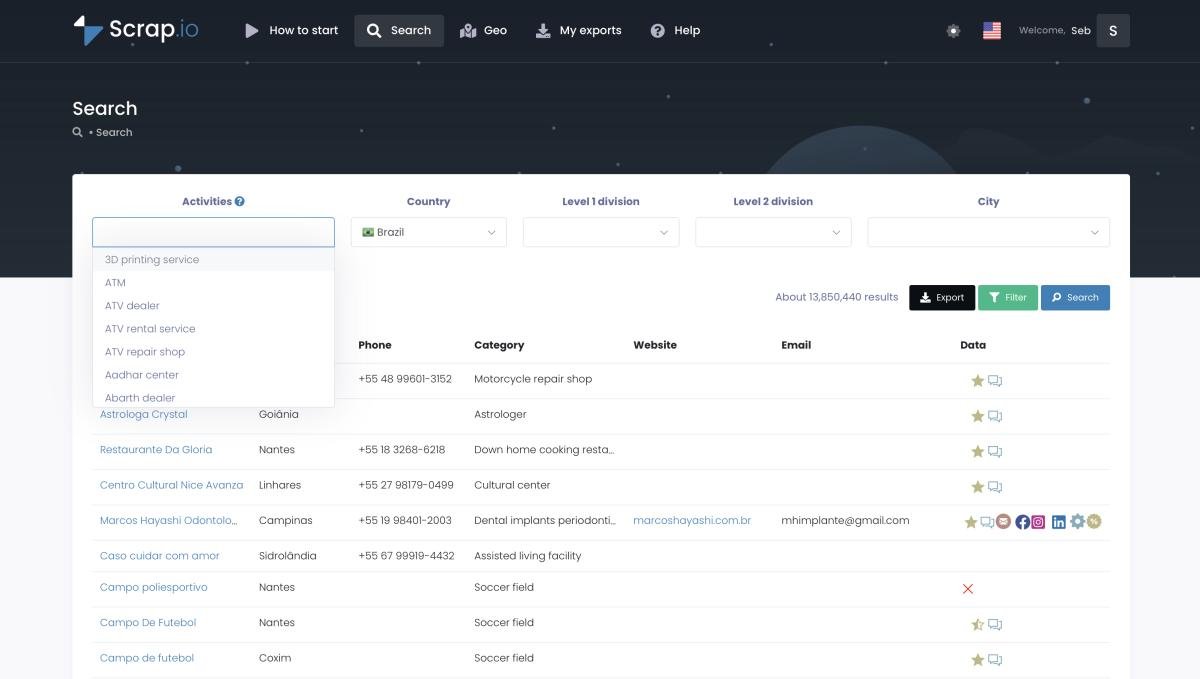
Plataformas como o Scrap.io permitem extrair dados de contato de empresas do Google Maps com um teste gratuito de 7 dias — incluindo 100 leads grátis para você testar na prática.
O Mercado de Web Scraping em 2026: Números e Tendências
Os números são bem reveladores. O mercado mundial de web scraping está avaliado em aproximadamente US$ 1,03 bilhão em 2025, segundo a Mordor Intelligence — com projeção de chegar a US$ 2,0 bilhões até 2030 (CAGR de 14,2%). Outra pesquisa da QY Research é ainda mais otimista: US$ 8,57 bilhões até 2032, com crescimento de 14,7% ao ano.
Mas o que está impulsionando esse crescimento todo? A adoção por setor diz tudo:
- ~70% dos desenvolvedores usam Python para fazer web scraping (Stack Overflow / comunidade, 2024-2025)
- BeautifulSoup lidera com 43,5% de adoção entre os frameworks de scraping (BrowserCat Developer Survey, 2024)
- 65% das empresas usam raspagem da web para alimentar projetos de IA e machine learning (BrowserCat, 2024)
- 81% dos varejistas americanos usam scraping automatizado de preços (Actowiz Solutions, 2025)
- O tráfego de bots e scrapers já representa 10,2% de todo o tráfego web mundial (F5 Labs, 2026)
E a IA? Ela está transformando completamente o setor. Scrapers tradicionais quebravam toda vez que um site atualizava o layout. Os novos sistemas com machine learning se adaptam sozinhos, identificam padrões e extraem dados mesmo de páginas que nunca viram antes. Para aprofundar nesse tema, vale conferir o futuro do web scraping com IA — o que está vindo por aí é impressionante.
Ferramentas de Web Scraping: Do Código ao No-Code
Aqui é onde as coisas ficam interessantes. Você não precisa saber programar para fazer web scraping em 2026. Mas se souber, tem opções ainda mais poderosas. De um web scraper simples em Python até plataformas SaaS que funcionam em dois cliques — vamos cobrir as três abordagens.
Com Python (Para Desenvolvedores)
Python domina o mundo do web scraping python por uma razão simples: tem bibliotecas incríveis e uma comunidade enorme. As principais são:
- BeautifulSoup — parsing de HTML simples e direto. A mais popular para iniciantes (web scraping python beautifulsoup)
- Requests — faz as requisições HTTP. Funciona junto com o BeautifulSoup
- Selenium — automatiza o navegador, ideal para sites com JavaScript dinâmico (web scraping python selenium)
- Scrapy — framework completo para projetos de maior escala
Exemplo básico de como fazer web scraping com Python e BeautifulSoup:
import requests
from bs4 import BeautifulSoup
url = "https://exemplo.com/empresas"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# Extrair todos os nomes de empresas
empresas = soup.find_all("h2", class_="nome-empresa")
for empresa in empresas:
print(empresa.text)Simples assim para casos básicos. Para sites que carregam conteúdo via JavaScript, você vai precisar do Selenium ou do Playwright. Para um guia completo sobre ferramentas de scraping com IA, confira este tutorial detalhado.
Extensões de Navegador (Para Iniciantes)
Se você quer fazer web scraping sem código, as extensões de Chrome são o caminho. As mais usadas são Instant Data Scraper, Data Miner e Web Scraper. Todas gratuitas para funções básicas.
O que elas têm em comum? Funcionam diretamente no navegador, são relativamente fáceis de configurar e servem bem para extrações pontuais. A limitação? Geralmente ficam restritas a 120 resultados por busca, não capturam emails ou redes sociais, e exigem que você fique presente durante a coleta.
Para quem quer usar ferramentas de web scraping gratuitas especificamente no Google Maps, existe um guia completo das melhores extensões Chrome para scraping que compara as opções com honestidade.
Plataformas SaaS / No-Code (Para Profissionais)
Aqui mora o salto de produtividade real. Ferramentas como Scrap.io, Octoparse e Apify eliminam toda a complexidade técnica e entregam dados limpos, estruturados e em escala.
O Scrap.io merece destaque especial para quem precisa de dados do Google Maps: você escolhe uma categoria, define uma localização (cidade, estado, país inteiro), aplica filtros — e em minutos tem um arquivo pronto para usar. Sem código, sem configuração complicada. O web scraper do Scrap.io já tem mais de 13,8 milhões de estabelecimentos indexados só no Brasil — um diferencial enorme para quem prospecta no mercado nacional. Confira o guia completo de scraping no Google Maps para ver tudo o que é possível extrair.
Comparação: Python vs Extensões vs SaaS
| Critério | Python | Extensões Chrome | SaaS (ex: Scrap.io) |
|---|---|---|---|
| Facilidade | Requer conhecimento técnico | Simples para iniciantes | Extremamente simples |
| Escala | Alta (ilimitada) | Baixa (~120 resultados) | Alta (país inteiro) |
| Custo | Grátis (mas tempo de dev) | Grátis / freemium | A partir de €49/mês |
| Dados incluídos | Depende do que você programar | Dados básicos (sem contato) | Email, redes, site, telefone |
| Manutenção | Requer atualização constante | Limitado | Zero manutenção |
| Tempo até resultado | Horas / dias | Minutos (limitado) | Minutos (escala total) |
A escolha certa depende do seu contexto. Desenvolvedor que precisa de algo customizado? Python. Teste rápido sem comprometimento? Extensão. Campanha de prospecção recorrente? Plataforma SaaS.
Quer rodar uma campanha de web scraping como nos casos reais que veremos abaixo? Comece com 100 leads gratuitos no Scrap.io — sem precisar configurar nada.
Web Scraping É Legal no Brasil? LGPD e Boas Práticas
Essa é a dúvida que todo mundo tem. E a resposta é: depende de como você faz.
O Que Diz a LGPD
A Lei Geral de Proteção de Dados (Lei 13.709/2018) não proíbe o web scraping de dados públicos. Mas ela estabelece princípios importantes: transparência, finalidade e necessidade. Isso significa que mesmo dados publicados abertamente em sites podem ter restrições de uso dependendo do contexto.
O princípio-chave aqui é: dados públicos ≠ uso irrestrito. Você pode coletar informações que uma empresa divulgou publicamente — mas precisa ter uma finalidade legítima e não pode usar esses dados de forma abusiva.
O Caso Curriculum vs Catho: Um Alerta Real
Em 2023, o Tribunal de Justiça de São Paulo condenou a Curriculum a pagar R$63 milhões à Catho por scraping abusivo de currículos cadastrados na plataforma. O caso ficou famoso no setor porque deixou claro um limite importante: mesmo que um dado esteja tecnicamente acessível, raspar informações pessoais de usuários em larga escala e de forma não autorizada configura concorrência desleal e viola a LGPD.
Esse caso não barra a raspagem de dados de informações empresariais públicas — mas serve de alerta para práticas predatórias envolvendo dados pessoais.
Janeiro de 2026: Brasil e UE Mais Próximos
Em janeiro de 2026, entrou em vigor o reconhecimento mútuo de proteção de dados entre o Brasil e a União Europeia. Na prática, isso significa que empresas que operam nos dois mercados precisam ter ainda mais atenção ao compliance — especialmente para operações de mineração de dados web em escala.
Boas Práticas de Conformidade
Para se manter dentro da lei ao fazer web scraping no Brasil:
- Respeite o robots.txt — é o arquivo que indica quais páginas um site permite que bots acessem
- Aplique rate limiting — não sobrecarregue os servidores com requisições excessivas
- Identifique seu bot — em projetos maiores, informe nos cabeçalhos HTTP quem está fazendo as requisições
- Foque em dados empresariais públicos — nome, telefone, email publicado no site, redes sociais: tudo isso é coletável
- Evite dados pessoais sensíveis — CPF, endereço residencial e informações privadas estão fora dos limites
- Respeite os termos de serviço da plataforma — mesmo que violar ToS não seja crime, pode resultar em bloqueios
Ferramentas como o Scrap.io já seguem essas diretrizes por design: coletam apenas dados que as próprias empresas tornaram públicos no Google Maps e nos seus sites. Para uma análise detalhada, confira o guia sobre a legalidade do scraping de dados públicos. E se você vai usar esses dados em campanhas de cold email, vale conhecer as boas práticas de compliance em outreach para não ter surpresas.
Casos Reais: Empresas Que Usam Web Scraping com Sucesso
Chega de teoria. Veja o que acontece quando um web scraper é aplicado de forma inteligente — com estratégia e as ferramentas certas:
itrinity (Portfolio SaaS)
Uma empresa de SaaS usou raspagem automatizada para turbinar sua geração de leads. O resultado? Saíram de 10 emails por dia para 400 por semana — um aumento de 40 vezes. Além disso, eliminaram 40 horas de trabalho manual por semana. (Fonte: Apify Blog)
Let's Fearlessly Grow (LFG)
Agência britânica de geração de leads que usou scraping de dados automatizado para substituir assinaturas caras de ferramentas como Apollo.io. Com a nova abordagem, passaram a gerar 2.500+ emails por dia por cliente — com dados frescos e verificados. (Fonte: Apify Blog)
Nodd Solutions
Agência de marketing digital de Sydney que combinou web scraping Google Maps com enriquecimento de dados. O resultado foi uma melhora significativa na qualidade dos leads e no pipeline comercial — com mais contexto sobre cada empresa antes do primeiro contato. (Fonte: Apify Blog)
Scrapus (Estudo Acadêmico)
Sistema de IA para geração de leads B2B que combinou data scraping com reinforcement learning. Os resultados foram notáveis: precisão e recall próximos de 90%, F1 score de 0,92 — e triplicou o volume de leads relevantes em comparação com métodos tradicionais. (Fonte: PMC/NCBI)
Mercado Livre Scraper (E-commerce Brasileiro)
Existe até um web scraper dedicado exclusivamente ao Mercado Livre — o maior marketplace da América Latina. Empresas usam essa ferramenta para monitoramento automatizado de preços, pesquisa de mercado e análise da concorrência diretamente na plataforma brasileira. Um caso de uso claro para qualquer varejista ou fabricante que opera no mercado nacional e precisa acompanhar a dinâmica de preços em tempo real. (Fonte: Apify Marketplace)
O padrão aqui é claro: quem usa extração de dados da web de forma estruturada e com as ferramentas certas sai na frente. Não é sobre quantidade de dados — é sobre dados frescos, filtrados e acionáveis.
Perguntas Frequentes (FAQ)
O que é web scraping e para que serve?
Web scraping (ou raspagem de dados) é o processo automatizado de extrair informações de sites da internet. Serve para monitoramento de preços em e-commerce, geração de leads B2B, pesquisa de mercado, monitoramento de reputação online e qualquer situação onde você precisa de dados estruturados de múltiplas fontes sem fazer isso manualmente.
Web scraping é legal no Brasil?
Sim, para dados públicos — desde que respeite a LGPD e os termos de uso das plataformas. A coleta de informações empresariais publicamente disponíveis (nome, telefone, email publicado, redes sociais) é permitida. O alerta fica para dados pessoais e para práticas abusivas, como ilustrou o caso Curriculum vs Catho, que resultou em uma multa de R$63 milhões por scraping predatório de currículos de usuários.
Qual a melhor linguagem de programação para web scraping?
Python, sem dúvida. Aproximadamente 70% dos desenvolvedores que fazem web scraping python usam principalmente as bibliotecas BeautifulSoup (43,5% de adoção), Selenium e Scrapy. Para quem prefere JavaScript, Node.js com Puppeteer ou Playwright também é uma boa opção — especialmente para sites com muito conteúdo dinâmico.
Qual a diferença entre web scraping e web crawling?
O rastreador web (crawler) navega entre páginas e indexa links — é o que o Googlebot faz. O scraper extrai dados específicos dentro de uma página. Na prática: o crawler descobre onde estão as informações, o scraper as coleta. Ferramentas profissionais geralmente combinam os dois num único fluxo.
É possível fazer web scraping sem saber programar?
Sim! Existem ótimas opções no-code. Para extração básica, extensões de Chrome como Instant Data Scraper e Data Miner funcionam bem. Para projetos maiores e com mais dados (incluindo emails e redes sociais), plataformas SaaS como o Scrap.io entregam resultados em escala sem nenhuma linha de código — e com filtros avançados que economizam muito tempo.
Quais são as melhores ferramentas de web scraping em 2026?
Depende do seu perfil. Para desenvolvedores: BeautifulSoup, Scrapy e Selenium (Python). Para iniciantes sem código: Instant Data Scraper (extensão Chrome). Para profissionais que precisam de escala e dados de contato: Scrap.io, Octoparse e Apify. O Scrap.io se destaca como web scraper especializado no Google Maps — é possível extrair todas as empresas de uma categoria em um país inteiro com dois cliques, incluindo email, telefone e redes sociais, com mais de 13,8 milhões de estabelecimentos indexados no Brasil.
Conclusão: Por Onde Começar?
Web scraping não é mais uma habilidade restrita a programadores avançados. Em 2026, com o mercado passando de US$ 1 bilhão e ferramentas no-code cada vez mais acessíveis, qualquer profissional pode usar coleta automatizada de dados para tomar decisões melhores, prospectar mais rápido e entender o mercado com mais profundidade.
O caminho é simples: se você quer aprender do zero com Python, comece com BeautifulSoup e Requests. Se quer resultados rápidos sem código, use as extensões de Chrome para testes pontuais. E se precisa de escala real — com dados de contato atualizados, filtros avançados e conformidade com a LGPD — plataformas como o Scrap.io são o caminho mais direto.
Teste o Scrap.io gratuitamente por 7 dias — obtenha 100 leads verificados instantaneamente e veja a diferença que dados frescos fazem na prática.
Fontes
- Mordor Intelligence — Web Scraping Software Market (2025)
- QY Research — Global Web Scraping Software Market Report (2025)
- F5 Labs — Bot Traffic Report (2026)
- BrowserCat Developer Survey (2024)
- Actowiz Solutions — E-commerce Price Monitoring Study (2025)
- Apify Blog — itrinity, Let's Fearlessly Grow, Nodd Solutions case studies
- PMC/NCBI — Scrapus: AI-Powered B2B Lead Generation via Web Scraping
- Apify Marketplace — Mercado Livre Scraper Brasil