I watched a friend lose three clients in one week last fall. Not because his data analysis sucked — it was actually sharp. He lost them because his scrapers kept dying. Price tracker for a DTC brand? Broke on Tuesday when the site pushed a minor CSS tweak. Competitor monitoring dashboard for a supplement company? Dead by Thursday — new Cloudflare rule. Job listing aggregator for a recruiter? Gone before Friday lunch. Something about a lazy-loaded React component that didn't exist the day before.
Fifteen scraper failures in a single month. He was spending more time patching extractors than doing the work people were paying him for. And that's the story for basically anyone still relying on rigid XPath expressions and hardcoded selectors in 2026.
It's also the reason the web scraping market is heading from $7.48 billion toward $38.44 billion by 2034 — nearly 20% CAGR according to Market Research Future. The companies pushing that growth aren't duct-taping CSS paths together. They're running AI web scraping — machine learning systems that figure out page structures on their own, adapt when layouts change, and pull data from sites they've never encountered.
ScraperAPI benchmarks their neural-network extractors at 95% accuracy on unfamiliar websites. BrowserCat's 2024 survey found 65% of companies already pipe scraped data straight into their AI projects. The shift didn't just start. It already happened while most people were still debugging broken selectors at 2 AM.
Video: AI Web Scraper vs Traditional SAAS — Thunderbit.com vs Scrap.io
- What Is AI Web Scraping? (And Why Traditional Scraping Is Dying)
- The AI Web Scraping Market in 2026: Key Numbers
- 5 AI Technologies Revolutionizing Web Scraping
- Best AI Web Scraping Tools & Platforms in 2026
- Real-World AI Web Scraping Use Cases (With Results)
- AI Web Scraping Compliance & Ethics in 2026
- The Future of AI Web Scraping: 2026–2030 Predictions
- FAQ — AI Web Scraping
What Is AI Web Scraping? (And Why Traditional Scraping Is Dying)
AI web scraping is the use of machine learning — NLP, computer vision, adaptive neural networks — to pull structured data from websites without hardcoded selectors or manual rules. Traditional scrapers crash the second a site renames a div. AI-powered web scraping recognizes patterns, grasps page context, and adjusts on its own. That's AI data extraction in a nutshell — and it's why the old way is dying fast.
I keep coming back to this analogy because it clicks. Old-school scraper: "Walk to the third shelf, grab the fourth book from the left." Move one book and those instructions are garbage. AI data extraction approach: "You know what a book looks like. Grab the marketing ones." Rearrange the entire library. Still works.
| Feature | Traditional Scraping | AI Web Scraping |
|---|---|---|
| Site layout changes | Breaks instantly | Self-heals, adapts |
| JavaScript rendering | Usually fails | Handles dynamic pages |
| Maintenance burden | Constant (60%+ of dev time) | ~40% less |
| Accuracy on new sites | Near zero | ~95% (ScraperAPI) |
| What it "gets" | Text in specific tags | Text + images + context |
| Coding requirement | Python/JS mandatory | Often zero-code |
That 40% maintenance reduction isn't a number somebody made up for a pitch deck. When your scraping team spends most of its week patching broken extractors — site changes, selectors die, fix it, repeat — nearly halving that overhead changes the economics of the whole operation. People start actually analyzing data instead of babysitting infrastructure. What a concept.
For a hands-on walkthrough of how AI data extraction works in real projects, our guide to using AI data scrapers covers the mechanics pretty thoroughly.
The AI Web Scraping Market in 2026: Key Numbers
Money talks. So let's see what it's saying.
The Business Research Company puts the web scraping software market at $0.99 billion in 2025, growing to $1.17 billion in 2026 — 18.5% CAGR. Market.us takes a wider lens and projects the broader market from $754 million (2024) to $2.87 billion by 2034 at 14.3% CAGR. Market Research Future sizes the AI-powered data extraction segment specifically at $7.48B, trending toward $38.44B.
The web scraping market size in 2026 makes more sense when you zoom out. The entire AI market is growing from $294 billion (2025) to $1,771 billion by 2032 per Fortune Business Insights — 29.2% annual growth. Web scraping isn't adjacent to that wave. It's riding it.
| Metric | Number | Source |
|---|---|---|
| Scraper/bot traffic (post-mitigation) | 10.2% of global web traffic | F5 Labs 2026 |
| Cloud-based scraping share | 68% | Mordor Intelligence |
| AI data project growth YoY | 400% | Zyte 2025 Report |
| Companies scraping for AI | 65% | BrowserCat 2024 |
| Proxy usage increase | 65.8% of pros report growth | Apify State of Web Scraping 2026 |
| Proxy spending up YoY | 58.3% | Apify Report 2026 |
Quick clarification on the bot traffic stats — you'll see the older HUMAN Security Platform number (36%) floating around alongside F5 Labs' 10.2%. Both are technically accurate. HUMAN counts raw traffic. F5 measures what's left after mitigation layers do their job. Either way, web scraping bot traffic statistics confirm the volume is staggering.
Adoption by Industry
Retail went first. And went hard. 81% of US retailers run automated data collection for competitive pricing now (Actowiz Solutions), a massive jump from 34% in 2020. Retail and e-commerce make up 36.7% of the total web scraping market per Market.us. When your competitor reprices 47 times in a day, you either automate or you lose margin. Simple as that.
Finance matched the intensity. 67% of US investment advisors use alternative data from web scraping per Mordor Intelligence. Press releases, social sentiment, earnings call transcripts, satellite imagery — anything that moves before the market. BFSI represents roughly 30% of web scraping market share in 2024.
Healthcare and real estate are ramping up. Recruitment is getting there. But retail and finance already crossed the point of no return. Everyone else is catching up.
5 AI Technologies Revolutionizing Web Scraping
Five technologies turned scrapers from brittle scripts into something resembling intelligence. Each attacks a different pain point that used to make data extraction a miserable job.
Smart Adaptive Scrapers
The headliner. Self-healing web scrapers — neural networks that learn page layouts and adapt when things change. No human intervention.
ScraperAPI shows 95% accuracy on sites the AI has literally never seen. Not sites it trained on. New ones. Show it a random Shopify store or a custom-built directory and it figures out where the names, prices, addresses, and reviews live. On its own.
DiscoverLife — a biodiversity database with ~3 million species photos — got hammered by millions of daily requests from adaptive AI crawlers in early 2025 (Nature journal). These weren't blind bots. They were intelligent web crawlers that refined extraction patterns with each request. Got progressively better at identifying and pulling the data they needed.
Maintenance savings: where traditional teams burn 60%+ of time in break-fix mode, AI brings that down by ~40%. Not marginal. Structural.
Predictive Data Extraction
This capability is genuinely impressive. Modern AI scrapers learn when data changes — and grab it before competitors even notice the update happened.
They figure out that Amazon reprices more during Prime Day. That SEC filings drop on a cadence. That restaurant menus refresh mid-week. Finance teams already run predictive scraping at millisecond scale — by the time a human reads the headline, the AI has parsed it, scored sentiment, checked cross-references, and triggered trades. Real-time scraping taken to an extreme.
NLP & Multimodal Extraction
Text-only extraction is a relic now. AI data extraction processes images, PDFs, video thumbnails, audio transcripts — all in context, all at once.
A real estate AI doesn't just pull listing prices. It analyzes property photos, reads agent descriptions for sentiment cues, cross-references comparable sales, and spits out a valuation estimate. Retail brands scrape Instagram to predict fashion trends a season out. Machine learning data extraction went from "read this <span>" to "understand this entire page and structure it." Night and day.
Best AI Web Scraping Tools & Platforms in 2026
I get asked "what's the best AI web scraper?" all the time. And the answer is always the same annoying thing: depends what you're scraping, your technical level, and your budget. A tool that's brilliant for general crawling might be completely useless for local business data. The reverse is equally true.
Here's where the major AI scraping tools land as of early 2026:
| Tool | Type | Best For | Price | Why It Wins |
|---|---|---|---|---|
| Browse AI | No-code SaaS | Beginners, marketers | Free + paid | Point-and-click, zero learning curve |
| Firecrawl | API | Devs, AI training data | Pay-per-use | Clean markdown output for LLMs |
| ScrapeGraphAI | Open source | Custom Python pipelines | Free (OSS) | LLM-powered, 15K+ GitHub stars |
| Crawl4AI | Open source | LLM training datasets | Free (OSS) | Purpose-built for AI data prep |
| Apify | Platform | Enterprise multi-source | From $49/mo | 100% success in benchmarks |
| Scrap.io | SaaS | Google Maps / local biz | From $49/mo | 200M+ listings, GEO extraction |
Browse AI = if you want an AI web scraping tool free of any coding. Literally click what you want and the AI handles extraction logic. Firecrawl = developer play — API that spits clean markdown directly into GPT or Claude. ScrapeGraphAI (590 monthly searches, climbing fast) = open-source LLM-powered scraper for people who want full Python control. Crawl4AI = specifically for assembling web scraping for AI training data.
On Scrap.io — where it fits, and more importantly where it doesn't. Scrap.io is not a general-purpose web scraper. It won't crawl arbitrary websites. What it does — and does better than anything else I've personally tested — is Google Maps business data at absolute scale. 200 million+ establishments. 195 countries. 5,000 requests per minute. You can extract every single plumber in Ohio or every hairdresser in France. Two clicks. No code. No server setup.
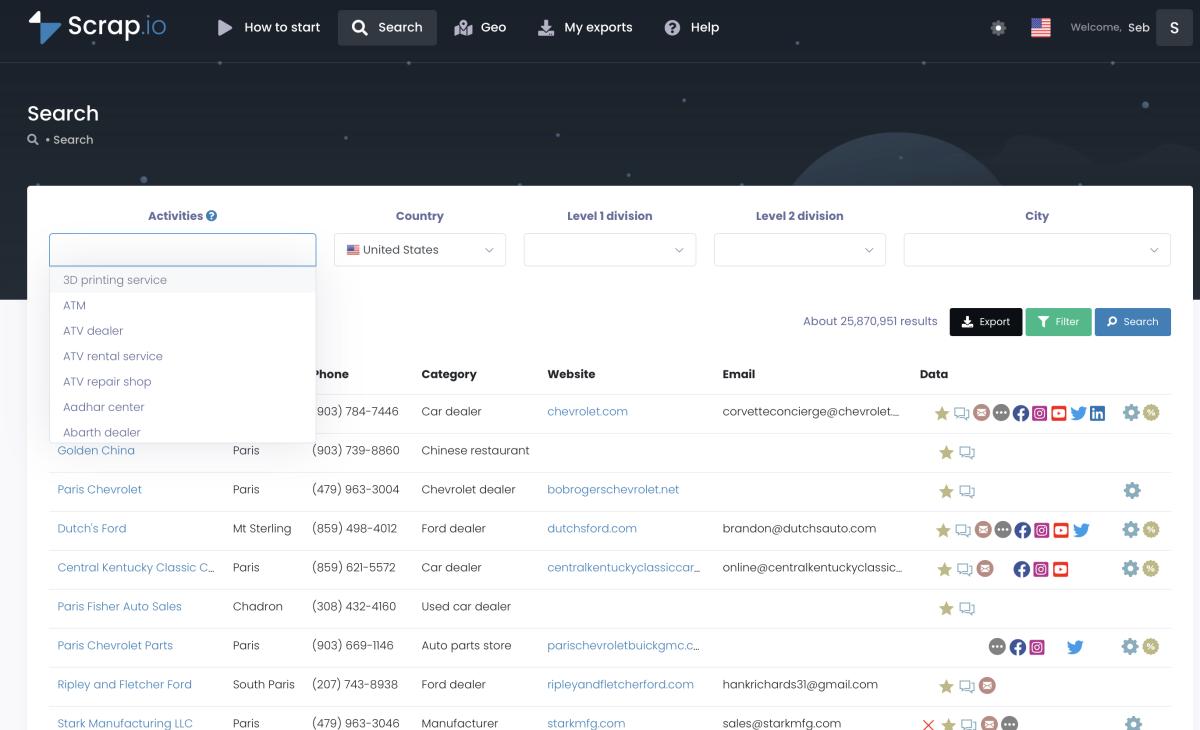
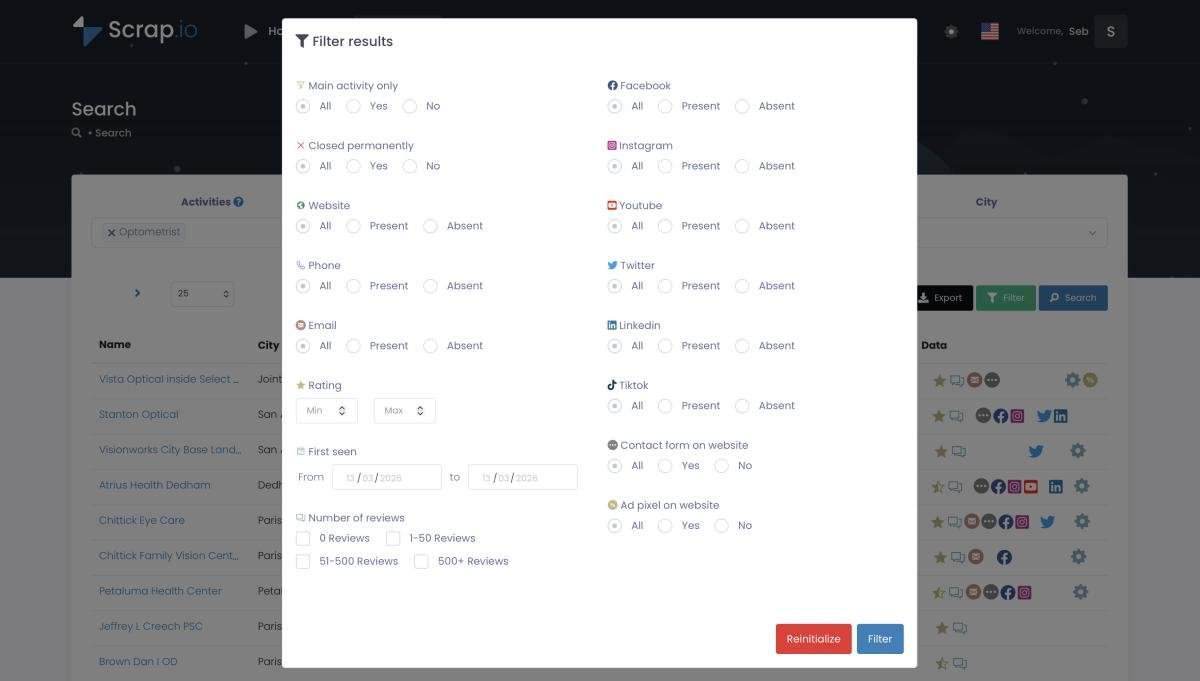
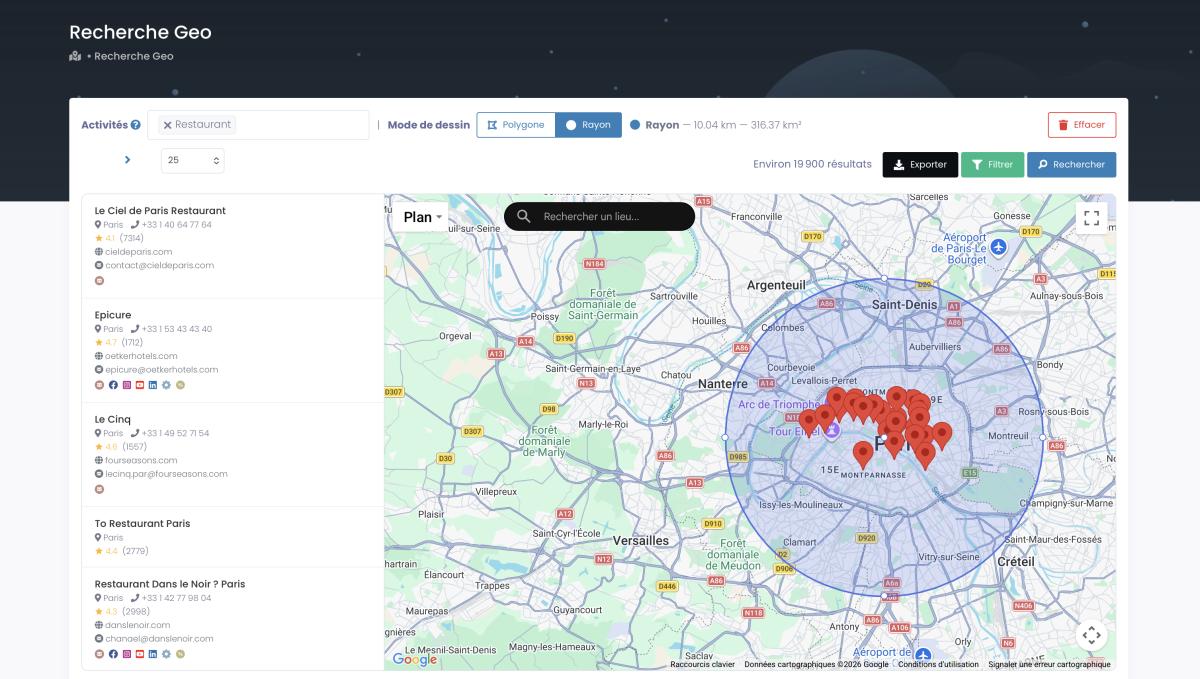
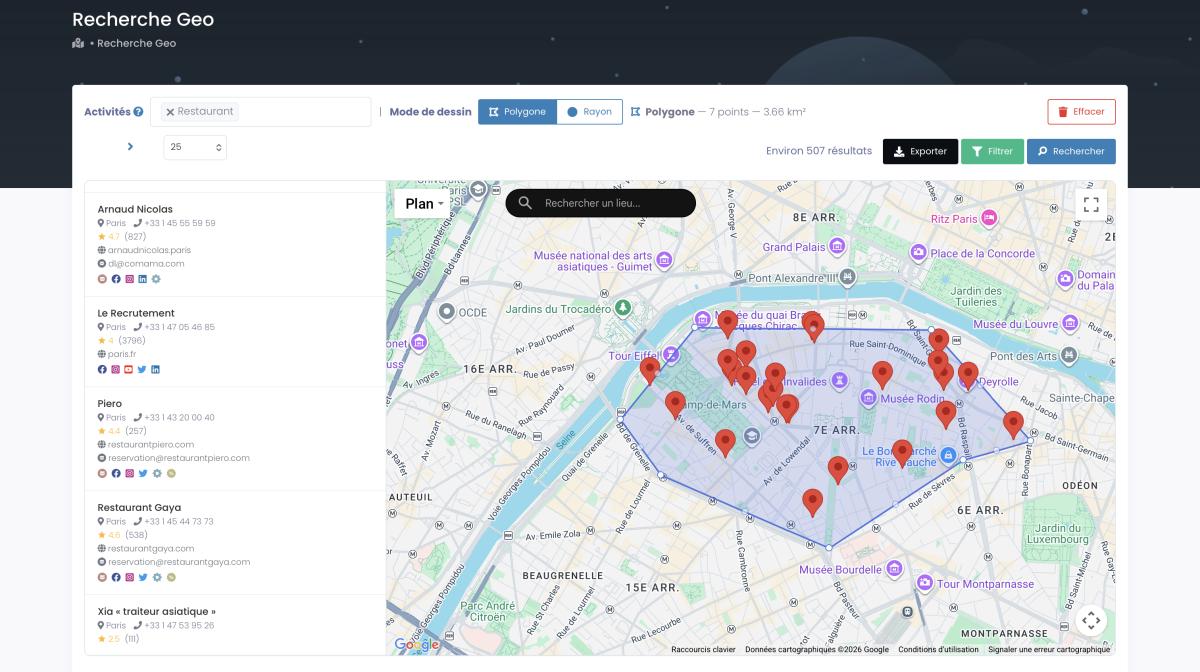
But here's the capability that nobody else in the SERP even mentions. Geographic precision scraping. Most tools let you filter by city or ZIP code. Scrap.io goes further — draw a polygon directly on the map, or set a radius around any GPS coordinate, and extract only businesses inside that zone. Every coffee shop within 2km of a specific intersection? Draw the circle. All retail stores within a custom neighborhood boundary? Draw the polygon. That's google maps scraping by radius and polygon — spatial intelligence that no general-purpose AI scraper comes close to offering.
OK, time for the uncomfortable part. There's a Reddit thread sitting at Google position 4 for "AI web scraping" with the gist of: "Tried AI for real-world scraping... it's basically useless." And you know what? They're not entirely wrong.
John Watson Rooney — arguably the most respected Python/scraping educator on YouTube — has said it plainly: AI is a cool trick, but it's not magical, and it's certainly not scalable for every use case. He's right. General-purpose AI scraping still chokes on deeply nested JS, complex multi-step pagination, and enterprise-grade anti-bot systems that analyze behavioral patterns at the session level.
Here's where AI web scraping genuinely shines: structured data from known site categories (product pages, directories, maps platforms), no-code extraction for non-technical teams, and adaptive crawling that cuts ongoing maintenance dramatically. It's not a solve-everything button. Anyone telling you that is trying to sell you something. But for the cases where it works? The productivity leap is brutal.
More tool context: our complete Google Maps scraping guide covers the full landscape of extraction methods, from APIs to Chrome extensions to dedicated platforms.
Real-World AI Web Scraping Use Cases (With Results)
Slides and projections are one thing. Actual implementations with measurable results? Different conversation entirely.
E-commerce dynamic pricing — millions of SKUs, every day. PromptCloud's 2026 report documents retailers running ML-powered price extraction across millions of product pages daily. And the AI isn't just copying "$49.99" into a spreadsheet. It understands that $49.99 is really $99.99 with a half-off coupon expiring Thursday, and that the same competitor ran an identical promo last Q3. Context — not just data. That's the difference between automated data extraction tools that are useful and ones that just produce noise.
Local business lead generation at scale. A marketing company extracted 11,734 businesses from Google Maps in under 45 minutes using Scrap.io. Names, verified emails, phone numbers, social profiles, website tech stacks — the full picture. Building a comparable B2B email database manually would take... honestly, weeks. Maybe months. The result was a segmented prospect file filtered for businesses with email addresses and 4+ star reviews. Ready for cold outreach within the hour.
Finance alternative data. Hedge funds scrape satellite imagery of parking lots to forecast quarterly earnings before the call. They monitor social sentiment in real time. Track shipping container movements. 67% of US investment advisors now run alternative data programs (Mordor Intelligence) — and web scraping is the primary acquisition layer for most of them.
Open-source AI dataset construction. ScrapeGraphAI crossed 15,000 GitHub stars by letting developers describe extraction requirements in plain English. "Get me the product name, price, and rating from this page." The LLM builds the scraper. No XPath. No CSS selectors. Web scraping for AI training data is becoming its own standalone subindustry, and tools like this are why.
Biodiversity and healthcare research. The DiscoverLife case — millions of daily AI bot requests indexing species data — showed both the power and the pressure. Pharma companies run similar pipelines to track clinical trial publications, extract study outcomes, and train predictive models. When data sources are semi-structured and constantly growing, AI scraping isn't optional. It's the only approach that works.
What happens after you scrape? If you're doing outreach, the pipeline is scrape → enrich → personalize → send. Our guides on AI cold email personalization for local businesses and automating CRM enrichment with Google Maps data cover those downstream steps. For local market strategy, how local SEO and data scraping feed into each other closes the loop.
AI Web Scraping Compliance & Ethics in 2026
Twenty million euros. That's what Italy's Garante fined a company for GDPR violations tied to data scraping. €20M. Numbers like that tend to sharpen people's focus on compliance pretty fast.
AI scraping compliance with GDPR isn't some box-checking exercise. It's structural — baked into architecture or it's a liability. Smart operators think about it in tiers:
Level 1 — Basic. Respect robots.txt. Don't slam servers. Skip personal data. Most companies sit here and think they're fine. Often they are. Until they aren't, and the fine is eight figures.
Level 2 — Progressive. Documented policies. Automated rate limiting. PII detection that catches and excludes sensitive data before it hits your pipeline. Audit trails on every job. You're building compliance into workflows, not hoping for the best.
Level 3 — Mature. Compliance-by-design. The AI itself embeds GDPR/CCPA logic — auto-detects personal data, anonymizes or skips it, respects consent signals, and generates compliance documentation. Eugene Yushenko (CEO of GroupBWT) has called this the emerging enterprise standard. He's probably right — it's the only model that scales to thousands of scraping jobs without manual legal review on each one.
The regulatory landscape, quickly:
GDPR (EU/UK): Demands legal basis for personal data processing. Publicly listed business info on Google Maps? Almost always fine. Scraping personal social media profiles without consent? Much riskier territory.
CCPA (California): Consumers get rights over their data — disclosure of what's collected, ability to opt out of sales. Web scraping compliance means knowing what you're collecting and having mechanisms to respect those rights.
robots.txt: Not legally enforceable in most jurisdictions, but ignoring it is the single fastest way to attract regulator attention. Every competent AI scraper respects it by default.
Scrap.io sidesteps the thorny stuff entirely — it extracts only publicly available business information from Google Maps. No personal data. No gray areas. GDPR compliant by architecture, not by afterthought. For how different tools approach compliance, see our comparisons with PhantomBuster and OutScraper.
The Future of AI Web Scraping: 2026–2030 Predictions
Some of these are already unfolding. Others need another 18–36 months. None of them are speculative — the building blocks already exist.
No-code takes over. AI web scraping without coding is already real (Browse AI, Scrap.io prove it daily). By 2028, it's the default. Natural language instructions — "find SaaS companies in Austin with under 50 employees" — and the AI handles the rest. Scheduling, error recovery, data cleaning, all of it. The AI data scraper guide already sketches this trajectory. No code AI web scrapers eat the market bottom-up.
Autonomous web scraping AI agents. Not "scrape this URL." More like "watch our competitive segment, flag pricing changes below threshold X, update the CRM, and draft an alert for the team." Multi-step, multi-source, decision-making agents that chain scrape → analyze → act. Early versions exist today. Broad adoption: probably 2028.
Scraping-as-a-Service kills DIY. 68% cloud adoption is just the start. Within three years, maintaining your own scraping infrastructure will feel as quaint as running your own email server. Platforms will own the pipes. Companies buy the output.
Edge computing + distributed extraction. Thousands of micro-scrapers on edge nodes, each making a handful of requests from different geolocations, sharing learned patterns, building collective intelligence. Harder to detect. Way more resilient. Faster.
Scraping converges with geospatial intelligence. This is the sleeper prediction — and the one I'm most confident about. The future isn't just smarter scraping. It's spatially precise scraping. Tools like Scrap.io already let you draw a radius or polygon on a map and extract only what falls inside. Now imagine combining that with satellite data, foot traffic patterns, and demographic overlays. Geo-targeted data scraping that identifies underserved markets at the street level. By 2028, this approach becomes standard across business data platforms.
Web scraping for AI training data becomes a standalone industry. With 65% of companies already feeding scraped data to AI models, demand for clean, structured, legally sourced training corpora is accelerating faster than supply. Firecrawl and Crawl4AI are built specifically for this. By 2030, the AI-training-data segment might be bigger than the entire rest of the web scraping market.
FAQ — AI Web Scraping
What is AI web scraping?
Machine learning — NLP, computer vision, neural networks — applied to automatic data extraction from websites. Traditional scrapers use hardcoded selectors that break constantly. AI scrapers recognize patterns and adapt without human input. One needs constant babysitting. The other mostly runs itself.
How does AI improve web scraping?
Five specific ways. Adaptive extraction that survives redesigns. Predictive scheduling that grabs updates before competitors. NLP that understands content meaning (not just tag positions). Computer vision for images and layouts. Multimodal processing that merges text, images, and video into structured output.
What are the best AI web scraping tools in 2026?
No single "best." Browse AI for no-code users. Firecrawl for devs feeding LLMs. ScrapeGraphAI for open-source Python flexibility. Apify for enterprise-scale multi-source jobs. Scrap.io for Google Maps and local business data. Pick based on your actual use case, not someone's ranking list.
Is web scraping legal in 2026?
Public data: generally yes. The Ninth Circuit affirmed it in LinkedIn v. HiQ Labs. European courts agree for public business info under GDPR. Gets murkier with personal data, login-gated content, or scraping that damages servers. AI scraping compliance GDPR means having a legal basis for any personal data you touch. Public business info on Google Maps is solid ground.
Can AI web scrapers work without coding?
100%. Browse AI and Scrap.io both do zero-code extraction — point at the data, hit export. No code AI web scrapers are one of the biggest market shifts in 2026, putting automated data extraction tools in the hands of marketers and analysts who've never touched Python.
What industries benefit most from AI web scraping?
Retail leads at 81% US adoption for pricing intelligence. Finance follows at 67% advisor usage for alternative data. Healthcare research, real estate, and B2B competitive intelligence round out the top verticals. Web scraping bot traffic statistics confirm it's become standard infrastructure, not a niche tactic.
How big is the AI web scraping market?
$1.17 billion in 2026 for web scraping software (TBRC), projected $2.28 billion by 2030. The AI-powered layer is much bigger — $38.44 billion by 2034 (Market Research Future). The web scraping market size 2026 data shows a market that's professionalizing at speed.
Is AI web scraping actually better than traditional scraping?
Static pages with stable HTML? Traditional scraping still works fine — no reason to overcomplicate it. Dynamic sites, JS-heavy pages, anti-bot-protected content, anything at scale? AI wins and the gap is widening. Self-healing web scrapers at 95% accuracy on unknown sites with 40% lower maintenance isn't an incremental upgrade. It's a different category.
Written by Sébastien — Co-Founder of Scrap.io. Writes about web scraping, lead generation, and data-driven marketing. Last updated: March 2026
Ready to generate leads from Google Maps?
Try Scrap.io for free for 7 days.