Video: How to Scrape Google Maps Without Python — Complete No-Code Tutorial
- Introduction to Google Maps Scraping in 2026
- The 7 Best Python Libraries for Google Maps Scraping (2026)
- Why Python Scraping Fails at Scale in 2026
- Scrap.io: The No-Code Google Maps Scraper
- Getting Started with Scrap.io (Step-by-Step)
- Advanced Filtering & GeoSearch
- Exporting & Analyzing Your Data
- Python vs No-Code: Complete 2026 Comparison
- Is It Legal to Scrape Google Maps?
- Conclusion
- FAQ
Introduction to Google Maps Scraping in 2026
The web scraping software market hit $1.17 billion in 2026, growing at 18.5% CAGR. That number alone tells you something: extracting business data from platforms like Google Maps isn't a nerdy side project anymore. It's an industry.
And Google Maps sits on top of it all — 225 million+ business listings across 195 countries. Restaurants, plumbers, dentists, agencies. Every single one with an address, a phone number, often a website. Some with emails buried on their contact page. All of it publicly visible to anyone with a browser.
Here's the thing, though. Knowing the data exists and actually getting it into a usable spreadsheet are two wildly different problems.
Most people's first instinct? Python. Write a script, fire up Selenium, scrape away. And sure — it works. Until it doesn't. (Spoiler: it stops working way faster than you'd expect.)
This guide breaks down the seven best Python libraries for Google Maps scraping, explains exactly why they fall apart at scale, and shows you how to scrape Google Maps without Python using a no-code tool that handles the entire process in about three minutes. We've been doing this at Scrap.io since 2021, so — fair warning — we have opinions. (If you want the full picture covering Python, API, and no-code methods side by side, there's a complete Google Maps scraping guide for that.)
The 7 Best Python Libraries for Google Maps Scraping (2026)
Python is great. Nobody's arguing otherwise. But when it comes to scraping Google Maps specifically, each library has trade-offs that most tutorials conveniently forget to mention. Here's the honest breakdown.
1. ZenRows — The Anti-Detection Specialist
ZenRows handles the biggest headache in scraping: getting blocked. It bypasses CAPTCHAs, manages TLS fingerprinting, and works on JavaScript-rendered pages. Solid. But it's a paid API — you're essentially outsourcing the hard part to someone else's infrastructure. At that point, you have to ask: why not outsource the entire scraping process?
2. Selenium — Dynamic Website Master
The old reliable. Selenium automates a real browser, which means it handles Google Maps' JavaScript-heavy interface. The downside? Slow. Resource-hungry. And maintaining Selenium scripts is like owning a boat — the joy fades fast once you realize how much upkeep it needs. (Ask anyone who's kept a Selenium scraper alive for more than six months. Go on. I'll wait.)
3. Requests — The Beginner's Friend
Requests was probably the first library you used to fetch a webpage. Clean syntax, easy to understand. But Google Maps loads everything via JavaScript. Requests doesn't execute JS. So you get a shell of HTML with none of the actual business data inside. Dead end for Maps, basically.
4. Beautiful Soup — The HTML Parser
Pair it with Requests and you can parse static HTML like a champ. The problem? Google Maps isn't static. Beautiful Soup can't see what JavaScript renders after page load. It's like reading a book with half the pages glued shut.
5. Playwright — Cross-Browser Automation
Microsoft's answer to Selenium. Faster, more modern, supports Chromium, Firefox, and WebKit. The learning curve is steep, though. And you still need to handle proxy rotation, infinite scroll pagination, and Google's ever-changing DOM selectors yourself. Fun if you enjoy that sort of thing. Masochism if you don't.
6. Scrapy — The Professional Framework
Built for crawling complex websites at scale. Scrapy is powerful — but it wasn't designed for JavaScript-heavy single-page apps like Google Maps. You'll need to bolt on Playwright or Splash to render pages, and at that point you're duct-taping two tools together.
7. urllib3 — The Requests Alternative
Lower-level than Requests. More control over connection pooling and retries. But the same fundamental limitation applies: no JavaScript execution, no Google Maps data. Wrong tool, wrong job.
Bottom line? Every Python library either can't render Google Maps at all, or requires significant infrastructure (proxies, CAPTCHA solvers, browser automation) to work. And even then, you're capped at roughly 120 results per search query. That's a Google limitation, not a code limitation.
Why Python Scraping Fails at Scale in 2026
OK so you've picked your library, written your script, and scraped 50 restaurants in Nashville. Congratulations. Now try scraping every restaurant in the United States.
Suddenly everything breaks.
Google's anti-bot detection got serious. TLS fingerprinting, behavioral analysis, CAPTCHA challenges that rotate every few weeks. A residential proxy that worked in January is flagged by March. Maintaining a working scraper against Google's defenses is a full-time job — and I mean that literally. Teams at companies like Outscraper employ engineers whose entire role is keeping scrapers alive.
The 120-result cap is brutal. Google Maps returns a maximum of ~120 listings per search. Want every dentist in Texas? You'd need to break that into hundreds of ZIP code-level queries, deduplicate across all of them, and handle pagination for each. A Python script that runs "fine" for one city becomes an engineering project for one state.
B2B data decays at 25-30% per year. Let that sink in. The contacts you scraped last quarter? A chunk of those phone numbers are disconnected. Businesses closed. Emails bounced. Your scraper doesn't know unless you run it again — and again, and again. Maintenance never ends.
Oh, and the costs. Proxy services run $30-100/month. Server time. Developer hours. One agency I talked to spent $2,000/month just on infrastructure for a Google Maps scraper that broke every two weeks. They switched to a no-code tool and cut that to $99/month. Sometimes the boring solution is the right solution.
Scrap.io: The No-Code Google Maps Scraper
Full disclosure — this is our tool. But let me explain why it exists, because the gap in the market was genuinely absurd.
We launched Scrap.io in October 2021. The idea was simple: give people the Google Maps data they need without forcing them to become Python developers first. Four years later, 50,000+ professionals use the platform. Rated 4.8 on Capterra, 4.9 on G2, 4.5 on Trustpilot. Clients include teams at Revolut, Amazon, Uber, L'Oreal, and a whole bunch of agencies and freelancers you've never heard of (but who are quietly crushing it with targeted lead lists).
What makes Scrap.io different from other Google Maps extractors?
Scale without code. Extract every business in an entire country — two clicks. Not a neighborhood. Not a city. A country. We've indexed 225,676,406 establishments. Our infrastructure handles 10,000 requests per minute. Try that with Selenium.
Pay only for useful contacts. Filters are applied before credits are consumed. Want only businesses with an email address? Toggle the filter. Only mobile phone numbers? Done. You don't waste money exporting 10,000 rows to delete 6,000 of them in Excel. That alone justifies the subscription for most users.
Real-time data, always fresh. No stale database scraped six months ago. Every extraction pulls live data from Google Maps and crawls the associated websites on the spot. Emails, social profiles, website tech stack — all current.
And honestly? The biggest selling point is time. A video outreach agency using Google Maps data reported 60% open rates and 4 meetings per week from their scraped lists. Another agency went from 50 outreach emails per week to 400 — saving 40 hours per month — by switching from manual scraping to automated extraction. That's an 8x improvement. Not because the tool is magic, but because it removes the bottleneck.
Getting Started with Scrap.io (Step-by-Step)
Three minutes. That's the honest setup time if you already know what niche you're targeting.
Step 1: Create your account. Head to scrap.io. Free trial gives you 50 searches and 100 export credits to test your target market.
Step 2: Pick your category and location. Scrap.io covers 4,000+ Google Maps categories. Type "plumber," "Italian restaurant," "yoga studio" — whatever you need. Then choose your geography. City level? Sure. State level? On the Professional plan. Entire country? Company plan. The search bar tells you how many results match before you spend a single credit.
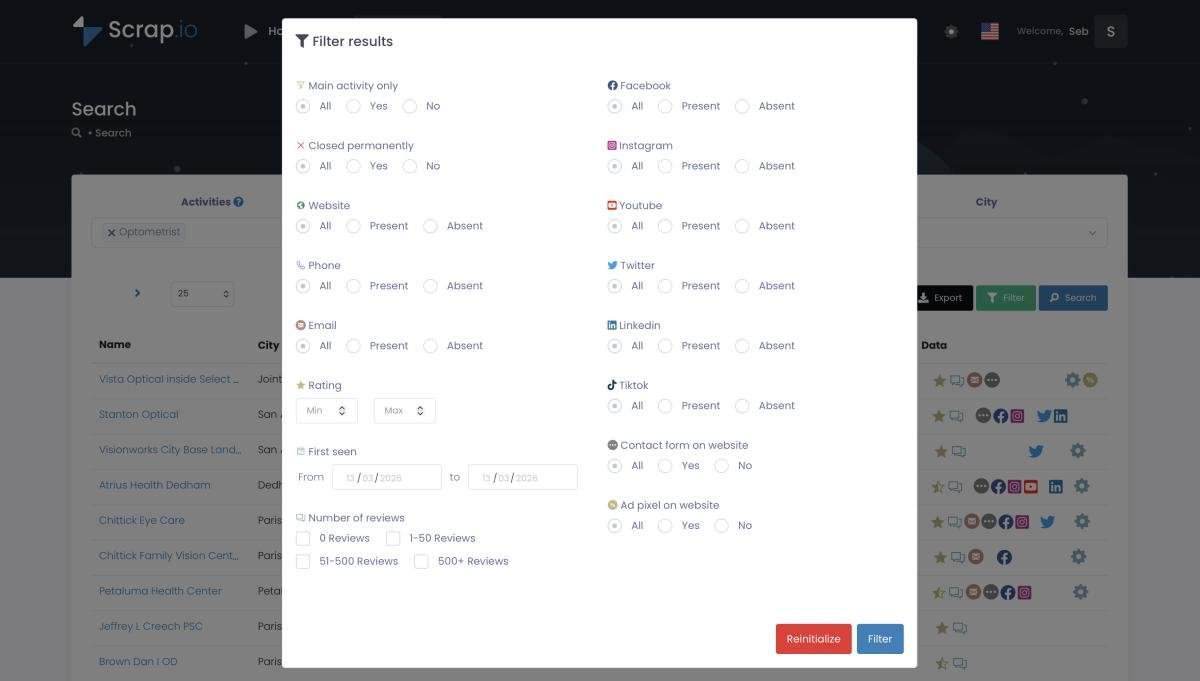
Step 3: Apply filters. This is where it gets interesting. Want only businesses with a website? With an email? With a Facebook page? Filter for minimum rating, review count range, claimed Google listing, presence of a contact form, even ad pixels on their website. Seventeen filters in total — all applied before extraction. Every filter narrows your list to exactly the prospects you want.
Step 4: Hit export. CSV or Excel. Your file includes business name, full address, phone number (with mobile/fixed classification), up to 5 classified emails per business, social media URLs, website technologies, Google Maps rating, review breakdown, and more. One credit = one business. Re-exports within 30 days are free.
Bref, the whole process is: search, filter, export, prospect. No terminal. No debugger. No 3 AM proxy rotation crisis.
And if you want to automate it completely? Scrap.io has a REST API and a native Make.com integration that lets you run extractions on autopilot, piping leads straight into your CRM.
Advanced Filtering & GeoSearch
Filtering is what separates a contact list from a prospect list. Anyone can dump 10,000 rows into a spreadsheet. The question is whether those 10,000 rows contain people who might actually buy from you.
Scrap.io's filters cover three categories:
Digital presence: website (yes/no), email (yes/no), phone (yes/no), social networks individually — Facebook, Instagram, LinkedIn, YouTube, X/Twitter, TikTok. Plus phone type classification: mobile vs. fixed vs. special. Target mobile numbers for SMS campaigns, fixed lines for cold calling. (Not available in the US/Canada for phone type, though.)
Business quality: Google Maps rating range, review count range, photo count, price range ($-$$$$), whether the listing is claimed, and whether the business is still operational. A 4.8-star restaurant with 300 reviews doesn't need the same pitch as a 2.9-star place with 6 reviews. Obviously.
Website signals: contact form present, ad pixels detected (Meta, Google Ads). A business running Facebook ads already understands paid acquisition — that's a warmer lead for most B2B services.
GeoSearch: Beyond Administrative Boundaries
Sometimes city limits don't match your service area. GeoSearch fixes that.
Radius mode — draw a circle around any point on the map, up to 500 km. Perfect for "every restaurant within 30 km of downtown Chicago."
Polygon mode — draw a custom shape directly on the map. Target a specific neighborhood, an industrial zone, or a coastal strip. Up to 1,000,000 km² on the Company plan.
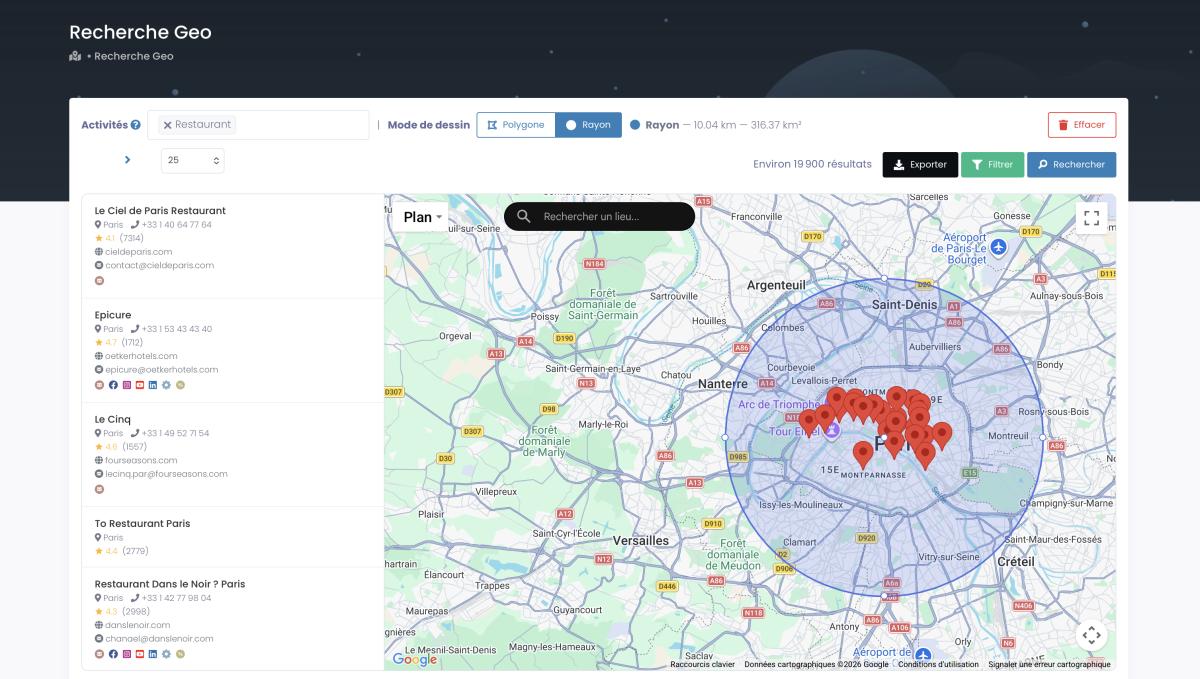
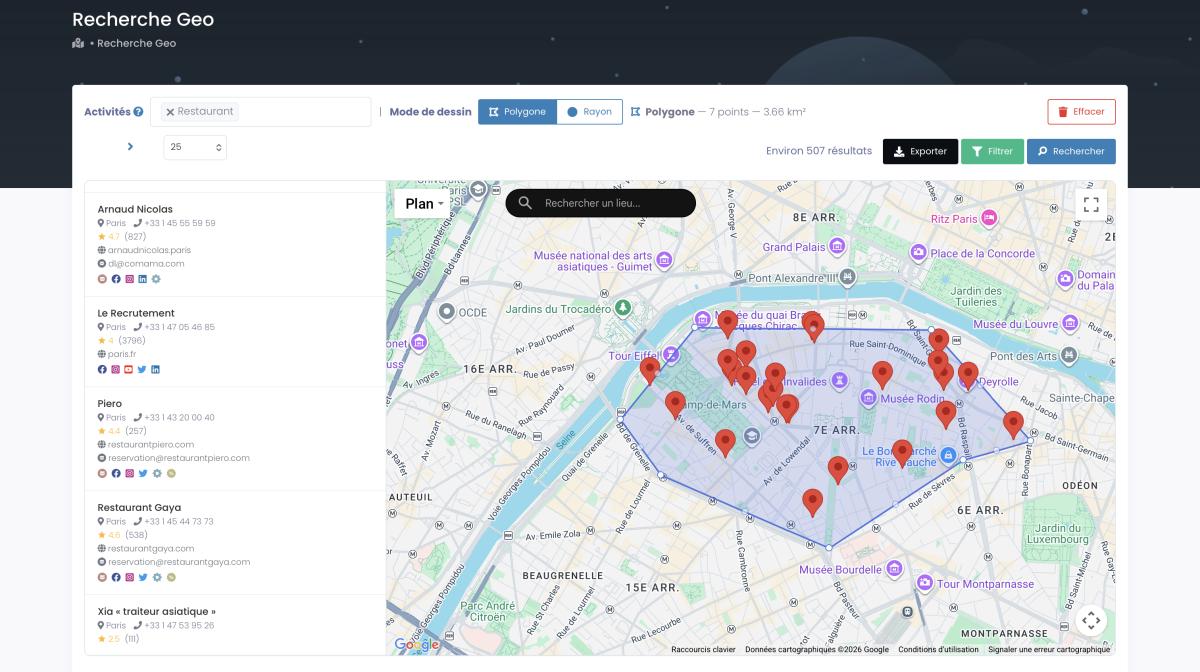
All filters remain active inside GeoSearch zones. Multi-category searches work too — combine "restaurant" + "bar" + "café" in a single query. That's something no Python script gives you out of the box.
Exporting & Analyzing Your Data
Your export lands as a CSV or Excel file. Color-coded columns: yellow for Google Maps data, orange for data enriched from the business website.
What's in there? Everything. Business name, closure status, primary and secondary categories, website, phone number with type (mobile/fixed/special), full address broken into street, city, postal code, state, country. GPS coordinates, Google Maps listing URL, owner name when available.
Then the email classification — and this is what most people get excited about. Scrap.io doesn't just dump email addresses. It categorizes them: individual email (with first name and last name extracted), contact email (info@, hello@), sales email, marketing email, finance email, admin email. Up to 5 per business. You know exactly who you're writing to before you hit send.
Social profiles: Facebook, Instagram, LinkedIn, TikTok, YouTube, X/Twitter. Website tech stack: CMS detection, analytics tools, ad pixels. And multiple contact page URLs per business.
The Clay team has documented how this kind of enriched Google Maps data feeds directly into niche lead generation frameworks — layer Scrap.io exports into Clay or your CRM, and you've got a pipeline that practically segments itself.
Oh, and also — no file size limit. Exports above 100,000 rows get split into batches inside a ZIP. Re-exporting the same data within 30 days? Free. Zero double-billing. That detail alone saves agencies hundreds of dollars per month.
Python vs No-Code: Complete 2026 Comparison
Enough talking. Numbers don't lie — here's the side-by-side.
| Criteria | Python (DIY) | Scrap.io (No-Code) |
|---|---|---|
| Setup time | 2-5 hours (minimum) | 3 minutes |
| Monthly cost | $280-600 (proxies + servers + dev time) | From $49/month (flat) |
| Technical skill required | Python, CSS selectors, proxy management | None |
| Results per search | ~120 (Google's cap) | Unlimited (own index) |
| Email extraction | Requires separate crawler | Built-in, classified by type |
| Data fields | 10-15 (depends on script) | 30+ per listing |
| Country-level extraction | Requires thousands of queries + dedup | 2 clicks |
| Data freshness | Whenever you run the script | Real-time at every export |
| Maintenance | Constant (DOM changes, anti-bot updates) | Zero |
| GDPR/CCPA compliance | Your responsibility | Handled |
A real-world test drives the point home. We compared DIY scraping vs Scrap.io on restaurants in France. DIY method: 52,000 results. Scrap.io: 139,000. Same country, same category. The DIY script missed more than half the listings because of the 120-result cap and incomplete city coverage.
Video: Google Maps API vs Scraping — Which Is Better in 2026?
On Reddit, the frustration is everywhere. A user on r/b2bmarketing shared how they "built a Google Maps scraper that scrapes for free" — then spent the next month fixing it. Another on r/n8n was looking for "a Google Maps Scraper designed specifically for n8n" — essentially trying to avoid writing Python at all. And on Quora, "How do I scrape Google Maps without coding?" is basically a perennial question with no satisfying answer. Until now.
There's also an n8n workflow for Google Maps scraping that's gotten decent traction — useful if you're already in that ecosystem, though it requires a data source behind it.
Is It Legal to Scrape Google Maps?
Short answer: yes, for publicly available business data. Long answer: still yes, but with nuance.
The hiQ Labs v. LinkedIn ruling (9th Circuit, 2022) established that scraping public data doesn't violate the Computer Fraud and Abuse Act. The Supreme Court's Van Buren decision backed that up. And Meta v. Bright Data (2024) confirmed that if you're not logged in, you haven't agreed to any Terms of Service.
Google's ToS do say "no scraping." But a ToS violation is a contractual dispute — not a crime. Massive difference.
GDPR in Europe allows B2B prospecting under legitimate interest for public business data. CCPA carves out publicly available business information entirely. Just include an opt-out in your outreach emails and you're solid.
Scrap.io only extracts publicly available business data and is GDPR and CCPA compliant. Every data point is traceable to its source. For the full legal breakdown: Is it legal to scrape Google Maps?
Conclusion
Python gives you control. It also gives you proxy bills, broken selectors at 3 AM, and a 120-result ceiling that makes country-level extraction almost impossible without serious engineering.
Scrap.io gives you the data. 225M+ businesses, 30+ fields per listing, real-time extraction, zero maintenance. The best Google Maps scraper isn't the one with the most elegant code — it's the one that actually delivers clean data when you need it.
Pick a category. Pick a location. Export. Prospect. That's the whole workflow.
Frequently Asked Questions
Can you scrape Google Maps without Python?
Yes. Tools like Scrap.io let you extract business data from Google Maps with zero coding. Pick a category, pick a location, apply filters, export. The platform handles proxies, CAPTCHA bypassing, and data formatting — you get a ready-to-use CSV or Excel file. There are also Chrome extensions for basic Google Maps scraping, though they're limited to ~120 results and don't extract emails.
What is the best no-code Google Maps scraper in 2026?
Scrap.io. It's the only Google Maps scraper that lets you extract data at country level in two clicks, with 30+ data fields per listing including classified emails. 225M+ businesses indexed, 195 countries, real-time data. Rated 4.8+ across Capterra, G2, and Trustpilot. Other options include Outscraper (pay-per-record, less transparent pricing) and Apify (powerful but developer-oriented).
Is it legal to scrape Google Maps?
For public business data — names, phones, addresses, ratings — yes. Court precedents from hiQ v. LinkedIn through Meta v. Bright Data confirm this. Google's ToS prohibit scraping, but violating ToS is a contract issue, not a criminal offense. GDPR allows B2B data processing under legitimate interest. Full analysis: legal guide.
How much does it cost to scrape Google Maps?
DIY Python scraping costs $280-600/month in proxies, servers, and maintenance time. Scrap.io starts at $49/month for 10,000 exports (Professional at $99 for 20,000, Agency at $199 for 40,000, Company at $499 for 100,000). Google's official Places API runs $17+ per 1,000 requests with far fewer data fields and a 5-review limit. For most teams, Scrap.io is the cheapest per-lead option once you factor in time saved.
What data can you extract from Google Maps?
With Scrap.io: business name, address, phone (with mobile/fixed classification), up to 5 classified emails, website, social profiles (Facebook, Instagram, LinkedIn, TikTok, YouTube, X), Google Maps rating and review breakdown, business hours, price range, photos, GPS coordinates, website technologies, ad pixels, contact forms, and SEO metadata. Over 30 fields per listing. For a deeper look at how to find emails specifically on Google Maps, there's a dedicated guide.
Ready to generate leads from Google Maps?
Try Scrap.io for free for 7 days.