De markt voor web scraping groeit van 0,99 miljard dollar in 2025 naar 1,17 miljard in 2026 — een groei van 18,5% op één jaar (The Business Research Company, januari 2026). En eerlijk gezegd is dat helemaal niet verrassend als je goed om je heen kijkt.
Neem Lars. Lars runt een salesteam bij een B2B-bedrijf in Amsterdam. Zijn concurrent weet altijd precies wat de markt doet. Nieuwe klanten, actuele prijzen, bedrijven die net een website hebben gelanceerd. Lars snapt niet hoe dat kan. Zijn team besteedt uren per week aan handmatig onderzoek — spreadsheets kopiëren, LinkedIn afstruinen, Google doorzoeken op zoek naar leads. En dan toch altijd achter de feiten aan lopen.
De concurrent scrapet. Punt.
Lees je dit artikel, dan ga ik ervan uit dat jij ook wilt begrijpen hoe dat werkt — en of je het zelf kunt inzetten. Dat gaan we uitzoeken. Inclusief het juridische stuk, want dat is in Nederland toch net wat ingewikkelder dan de meeste gidsen je laten geloven. Databankrecht, Autoriteit Persoonsgegevens, de zaak-Funda: de meeste internationale artikelen slaan dat gewoon over. Wij niet.
- Wat is web scraping? (Definitie & betekenis)
- Hoe werkt web scraping? (Stap voor stap)
- Waarvoor wordt web scraping gebruikt in 2026?
- Web scraping tools en methoden
- Web scraping met Python
- Is web scraping legaal in Nederland? (AVG & databankenrecht)
- Web scraping van Google Maps met Scrap.io
- Cijfers & trends 2026
- Praktijkvoorbeelden
- Veelgestelde vragen (FAQ)
- Conclusie
Wat is web scraping? (Definitie & betekenis)
Web scraping is het geautomatiseerd ophalen van gegevens van websites. Je stuurt een softwareprogramma op een website af, dat programma leest de pagina zoals jouw browser dat zou doen, en het haalt daar precies de informatie uit die jij nodig hebt — prijzen, e-mailadressen, teksten — zonder dat je zelf op knoppen hoeft te klikken. Ook bekend als webscraping, scrapen, data-extractie, screen scraping of web harvesting.
Dat is de scraping betekenis in één alinea. Maar er is een veelgestelde vraag die ik meteen wil wegnemen: wat is het verschil tussen web scraping en web crawling? Crawling is wat zoekmachines doen — pagina's systematisch indexeren en doorlinken. Scraping gaat verder: je extraheert specifieke, bruikbare data uit die pagina's. Google crawlt. Jij scrapt.
Zo'n web scraper — of web crawler, zo je wil — bestaat altijd uit drie onderdelen die samenwerken:
- Crawler — het stuk dat de website bezoekt en eventueel links volgt naar andere pagina's.
- Parser — de logica die de HTML-code analyseert en precies de velden uitpikt die je nodig hebt.
- Opslag — alles wat gevonden is, belandt in een CSV, Excel, database of direct in je CRM.
Dat is de kern. De rest is implementatiedetail.
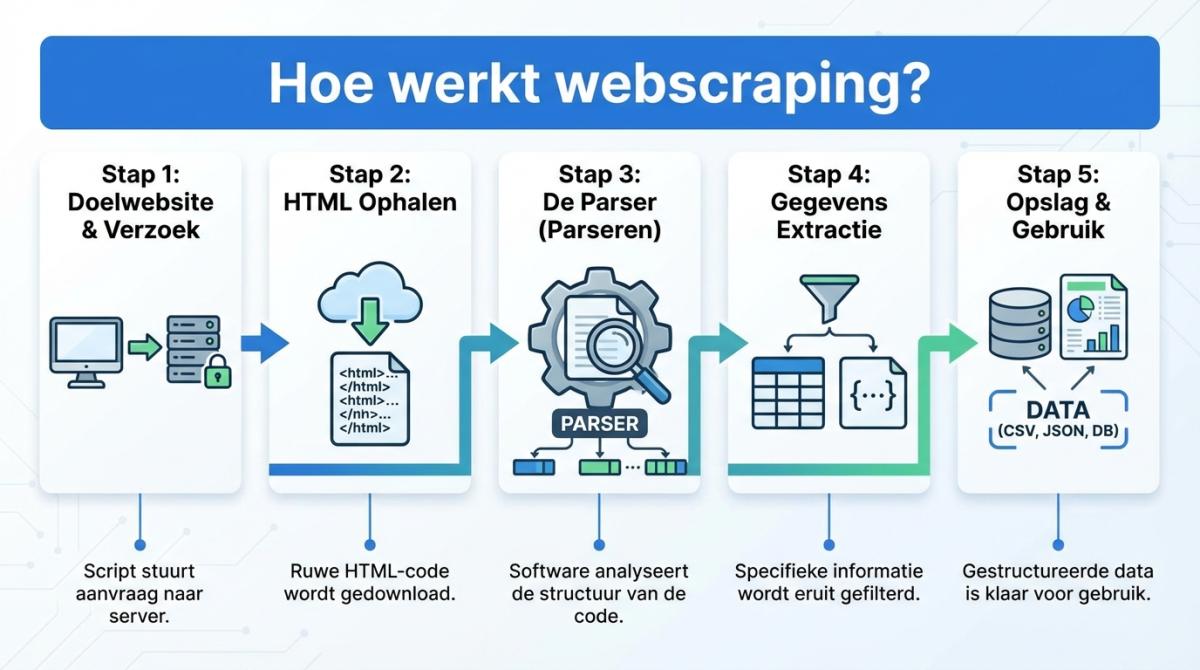
Hoe werkt web scraping? (Stap voor stap)
Hoe werkt web scraping nou concreet? Elk scraping-project doorloopt min of meer dezelfde vier stappen: Verzoek → Ophalen → Parsen → Opslaan. Onthoud die vier woorden, dan snap je 90% van het vak.
- Verzoek versturen — De scraper stuurt een HTTP-verzoek naar de doelwebsite, precies zoals een browser dat doet. De server reageert met HTML.
- Pagina-inhoud ophalen — Die HTML-broncode is nu beschikbaar voor analyse. Inclusief alle tekst, links, afbeeldingen en structuurelementen.
- Data parseren — Via CSS-selectors of XPath herkent de parser welke elementen interessant zijn. Naam hier, telefoonnummer daar, e-mailadres verderop.
- Opslaan en gebruiken — De data wordt schoongemaakt en weggeschreven. In een CSV, JSON, database, of rechtstreeks naar je CRM of marketingtool.
Vier stappen. Van website naar bruikbare data. De magie zit hem in stap vier: wat je met die data doet, bepaalt het verschil tussen een leuk experiment en een serieus concurrentievoordeel.
Trouwens — deze vraag leeft breed. Op Reddit staat in r/datascience een veelgelezen draad, "My ultimate guide to web scraping", waarin een practitioner precies dezelfde volgorde beschrijft: verzoek, ophalen, parsen, opslaan. Als de community het zo samenvat, zit je goed.
Waarvoor wordt web scraping gebruikt in 2026?
Goed, de theorie is helder. Maar waarom gaan bedrijven hier eigenlijk voor? Welke problemen lost het op?
Prijsmonitoring & e-commerce
Dit is de grootste drijfveer voor web scraping wereldwijd. 81% van de Amerikaanse retailers gebruikt inmiddels geautomatiseerde prijsscraping voor dynamische herprijsstrategieën — tegenover slechts 34% in 2020 (Actowiz / Mordor Intelligence, 2025). In vijf jaar meer dan verdubbeld. Dat is geen trend meer, dat is de standaard.
Voor Nederlandse e-commercespelers zoals bol.com en Coolblue is dit dagelijkse operatie. Je kunt niet handmatig bijhouden wat concurrenten doen met hun prijzen als die elke paar uur worden aangepast. Automatisering is hier geen keuze meer.
Leadgeneratie & B2B-prospectie
Hier wordt het voor veel Nederlandse bedrijven écht interessant. Stel: je wilt alle installatiebedrijven in Noord-Holland benaderen. Of alle accountantskantoren zonder LinkedIn-aanwezigheid. Dat handmatig opbouwen kost weken. Met een gerichte data scraper of een platform als Scrap.io heb je die lijst in twee klikken — inclusief e-mailadressen, telefoonnummers en social media-profielen, rechtstreeks uit Google Maps.
Dit is trouwens waar scraping en leadgeneratie elkaar raken. Wie serieus kwalitatieve leads wil genereren, begint bij verse data — niet bij een gekochte lijst van zes maanden oud. Het is ook een goedkoper alternatief voor een kant-en-klare B2B-database kopen, met als bonus dat je die data daarna direct kunt inzetten voor e-mailmarketing of koude acquisitie.
Marktonderzoek, concurrentieanalyse & vastgoed
Hoe ziet je concurrentiepositie eruit? Wat zeggen klanten op reviewplatforms over een concurrent? Welke vacatures zetten bedrijven uit — een indirecte indicator van hun groeistrategie? Dit zijn allemaal web scraping voorbeelden die dagelijks geld opleveren.
In Nederland is de vastgoedsector een bijzonder relevant voorbeeld. Funda heeft in dit land een bijna monopoliepositie op woningadvertenties, wat de vraag oproept: mag je Funda scrapen? (Kort antwoord: commercieel niet. Maar we gaan er in de juridische sectie flink dieper op in — het is namelijk een leerzaam verhaal.)
AI-training & datawetenschap
Dit is iets wat mensen buiten de tech-wereld vaak niet beseffen: de meeste grote taalmodellen zijn mede getraind op gescrapete webdata. En dat segment ontploft. De AI-gedreven scraping-markt groeit tussen 2024 en 2029 met meer dan 3,15 miljard dollar, een CAGR van 39,4% (Research and Markets). Dat is bijna dubbel zo snel als de bredere markt. Enorm.
Liever geen scraper onderhouden? Scrap.io haalt bedrijfsdata realtime uit Google Maps — 225 miljoen geïndexeerde vestigingen in 195 landen, filterbaar op e-mail, telefoon of social media vóór je één krediet uitgeeft. Geen script om te repareren, geen captcha's. Start gratis — 7 dagen, 100 leads inbegrepen.
Web scraping tools en methoden
Er zijn grofweg vier manieren om te scrapen: een no-code browser-extensie, zelf code schrijven in Python, een web scraping API, of een SaaS-platform dat het zware werk doet. Welke aanpak voor jou werkt, hangt af van je doel, je budget en hoeveel tijd je hebt.
No-code & Chrome web scraping
Goed nieuws als je geen developer bent: de no-code tools van 2026 zijn verrassend krachtig zonder dat je ook maar één regel code schrijft. 62% van de scraping-projecten draait inmiddels op een no-code of low-code aanpak (Actowiz, 2026). Voor kleinere eenmalige taken zijn Chrome web scraping-extensies zoals Web Scraper of Instant Data Scraper een prima keuze — tabellen en lijsten in seconden geëxporteerd naar CSV, gratis.
Wil je scrapen zonder programmeren maar wél op professionele schaal? Dan is een gespecialiseerd SaaS-platform bijna altijd goedkoper in totale kosten dan een eigen Python-oplossing bouwen en onderhouden.
AI-scrapers: hype of echt beter?
Iedereen roept "AI" tegenwoordig. Werkt het ook? Deels. Machine learning-modellen herkennen steeds beter de structuur van pagina's, zelfs als die verandert — met tot 85% minder onderhoud als resultaat (GroupBWT, december 2025). Dat scheelt echt. Maar volledig AI-gegenereerde scraping zonder controle levert nog steeds rommel op zodra een site tegenstribbelt. Gebruik AI als versneller, niet als wondermiddel.
De onderstaande video zet een klassieke SaaS-aanpak naast een AI-scraper — handig als je twijfelt welke kant je op moet.
Video: AI Web Scraper vs Traditionele SaaS (Thunderbit vs Scrap.io)
Via een web scraping API
Een web scraping API zit tussen no-code en volledig zelfbouw in. Je stuurt een verzoek, je krijgt gestructureerde JSON terug — proxy's, retries en captcha-afhandeling zitten er onder de motorkap in. Het is de snelst groeiende categorie (+27% zoekvolume jaar op jaar), precies omdat het schaal combineert met weinig onderhoud. Scrap.io heeft bijvoorbeeld een eigen REST API (300 verzoeken per minuut, inbegrepen in elk plan) zodat je data direct in je eigen systeem trekt.
Welke aanpak past bij jou? Vergelijkingstabel
| Criterium | No-code extensie | Python (DIY) | API | SaaS (Scrap.io) |
|---|---|---|---|---|
| Technisch niveau | Laag | Hoog | Gemiddeld | Zeer laag |
| Onderhoud | Weinig | Veel | Weinig | Geen |
| Schaal | Matig | Hoog (mits kennis) | Hoog | Hoog |
| Kosten | Gratis–laag | Laag (jouw tijd) | $50–$300/mnd | v.a. €35/mnd |
De keuze is eigenlijk niet zo moeilijk. Ben je developer en wil je volledige controle: Python. Wil je snel resultaat zonder code: no-code, API of SaaS. Meer weten over de tools zelf? Wikipedia heeft een degelijke, neutrale uitleg over webscraping als je de technische achtergrond wilt.
Web scraping met Python
Web scraping met Python is verreweg de meest gebruikte technische aanpak. Python web scraping draait om drie libraries die je moet kennen:
- BeautifulSoup — ideaal voor statische HTML-pagina's, lage leercurve, veel gebruikt voor eerste projecten.
- Scrapy — krachtig framework voor grootschalige scraping met ingebouwde crawling-logica; de keuze als je duizenden pagina's wilt verwerken.
- Selenium — onmisbaar voor websites die JavaScript laden na paginaweergave; werkt met een echte browser in de achtergrond.
Een concreet voorbeeld — reviewscores en -teksten ophalen van een bedrijfspagina via BeautifulSoup:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/restaurant/amsterdam"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
reviews = soup.find_all("div", class_="review-item")
for review in reviews:
score = review.find("span", class_="rating").text
tekst = review.find("p", class_="review-text").text
print(f"Score: {score} — {tekst[:80]}...")
Werkt prima voor eenvoudige gevallen. De officiële Real Python-gids over BeautifulSoup is trouwens het beste startpunt als je dit zelf wil leren. Maar — en dit is een grote maar — zodra een site captcha's toepast, JavaScript gebruikt of IP-adressen blokkeert, wordt onderhoud al snel tijdrovend. Dat is precies waar no-code en SaaS-tools de overhand nemen.
Is web scraping legaal in Nederland? (AVG & databankenrecht)
Dit is het deel waar Nederland net even anders is dan de rest. En dat heeft een concrete reden.
Web scraping is in principe legaal wanneer je openbaar beschikbare, niet-persoonsgebonden gegevens verzamelt. De AVG (GDPR) beschermt persoonsgegevens. Het scrapen van zakelijke informatie zoals prijzen, bedrijfsgegevens en productdata is doorgaans toegestaan, mits je de robots.txt respecteert en geen auteursrechten of databankrecht schendt.
Maar let op — en hier wordt het serieus. De Autoriteit Persoonsgegevens stelt in haar Handreiking scraping (2025) glashelder: scraping door private partijen en particulieren is "vrijwel nooit toegestaan" zodra er persoonsgegevens bij betrokken raken. Dat is een fors statement, en het is uniek voor Nederland dat de toezichthouder er zo expliciet over is. E-mailadressen van individuele mensen scrapen zonder grondslag? Nee. Zakelijke bedrijfsgegevens — een KvK-nummer, een algemeen bedrijfstelefoonnummer? Een stuk gunstiger terrein.
Het databankrecht: de Nederlandse bijzonderheid
Nederland heeft naast de AVG ook het databankrecht — en dat is iets waar de meeste internationale gidsen over web scraping helemaal niet over spreken. Terwijl het hier juist cruciaal is.
Een database is beschermd als de maker er substantieel in heeft geïnvesteerd. Die bescherming geeft de eigenaar het recht om te voorkomen dat anderen grote stukken van de database overnemen of hergebruiken. Een database hoeft geen kernactiviteit te zijn om beschermd te zijn — het gaat om de investering in de opbouw.
Het geval Funda: een waarschuwend voorbeeld
Wil je weten hoe het databankrecht in de praktijk werkt? Kijk naar Funda.
Funda heeft een beschermd databankrecht op hun woningadvertenties-overzicht. Dat heeft de Hoge Raad al in 2002 bevestigd, toen De Telegraaf met hun dienst "El Cheapo" Funda-zoekresultaten scraapte en toonde in een eigen interface. Dat mocht niet. Funda had flink geïnvesteerd in de opbouw van die database.
Interessant genoeg: een latere partij, Zoekallehuizen, had het slimmer bekeken. Die scraapten niet Funda zelf, maar de individuele makelaarssites — waar dezelfde huizen ook stonden. Dat werd wél toegestaan, omdat individuele makelaars geen database van woningadvertenties exploiteren; zij verkopen huizen. Nuance telt hier echt.
Kortom: wil je vastgoeddata scrapen in Nederland, scrape dan de individuele makelaarssites — niet de aggregator. En controleer altijd de robots.txt en de gebruiksvoorwaarden.
AVG, robots.txt en HiQ vs. LinkedIn
Buiten het databankrecht gelden de gebruikelijke regels:
- AVG — Persoonsgegevens vereisen een wettelijke grondslag. B2B zakelijke data valt er doorgaans buiten.
- robots.txt — Juridisch niet bindend, maar negeren is een risico. Goed gebruik: altijd respecteren.
- Terms of Service — Verbiedt een site scraping in de voorwaarden, dan is dat een civielrechtelijk risico, ook al is de data publiek.
Het Amerikaanse precedent HiQ vs. LinkedIn stelde dat scraping van publiek beschikbare data in beginsel is toegestaan. Dat argument wordt ook in Europa gebruikt, al speelt het databankrecht hier dus een extra rol. Op Reddit loopt in r/webscraping een terugkerende draad, "What is web scraping and how is it used?", waar practitioners exact dezelfde conclusie trekken: publieke zakelijke data is meestal oké, persoonsgegevens zijn het mijnenveld.
Alleen publieke B2B-data, AVG-proof. Scrap.io verzamelt uitsluitend bedrijfsinformatie die ondernemers zelf publiek op Google Maps hebben gepubliceerd — traceerbaar tot de bron, RGPD- en CCPA-compliant. Precies het meest comfortabele juridische segment. Start gratis.
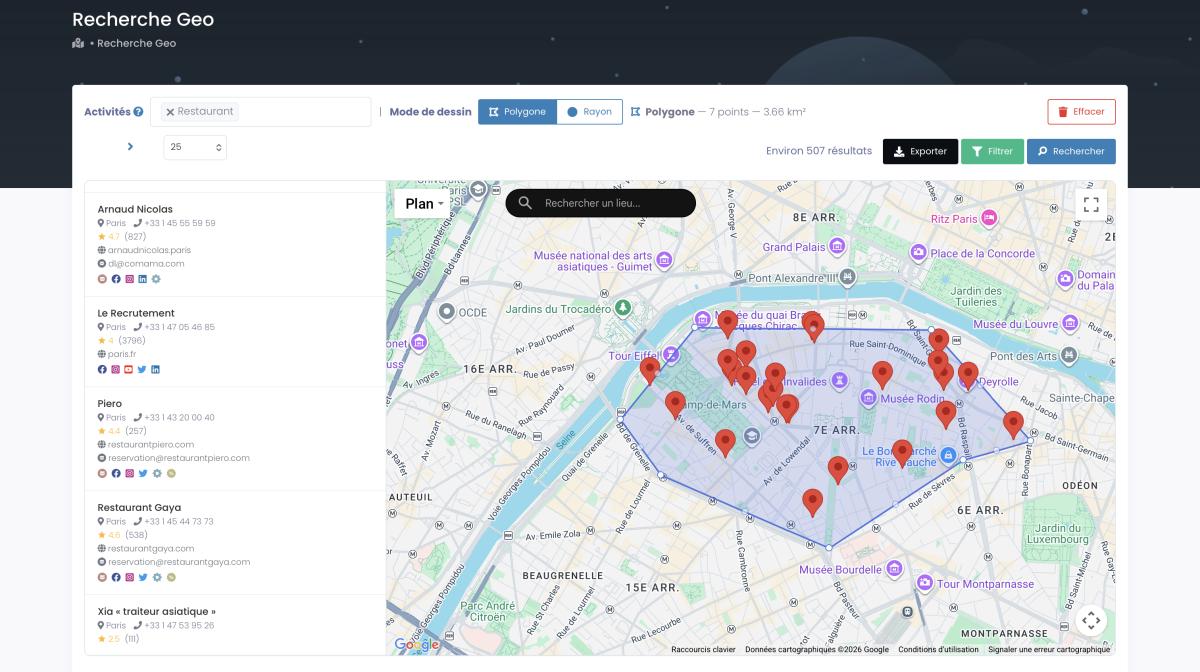
Web scraping van Google Maps met Scrap.io
Oké, genoeg theorie. Hoe ziet web scraping google maps er in de praktijk uit zonder dat je een regel code schrijft? Zo dus.
Google Maps is waarschijnlijk de rijkste openbare bron van lokale bedrijfsdata die er bestaat: naam, adres, telefoon, website, reviews, openingstijden. Het probleem is dat handmatig kopiëren niet schaalt. Probeer maar eens 2.000 kappers in de Randstad met de hand over te tikken. Ik wacht wel.
Scrap.io lost dat op met een live database in plaats van een crawler die je moet onderhouden. Je zoekt op categorie (4.000+ activiteiten), je kiest een zone — van één stad tot een heel land — en je exporteert. De data wordt realtime opgehaald op het moment dat jij zoekt, dus geen export van zes maanden oud. Vanuit daar rolt het zo je CRM-systeem in, klaar om op te volgen.
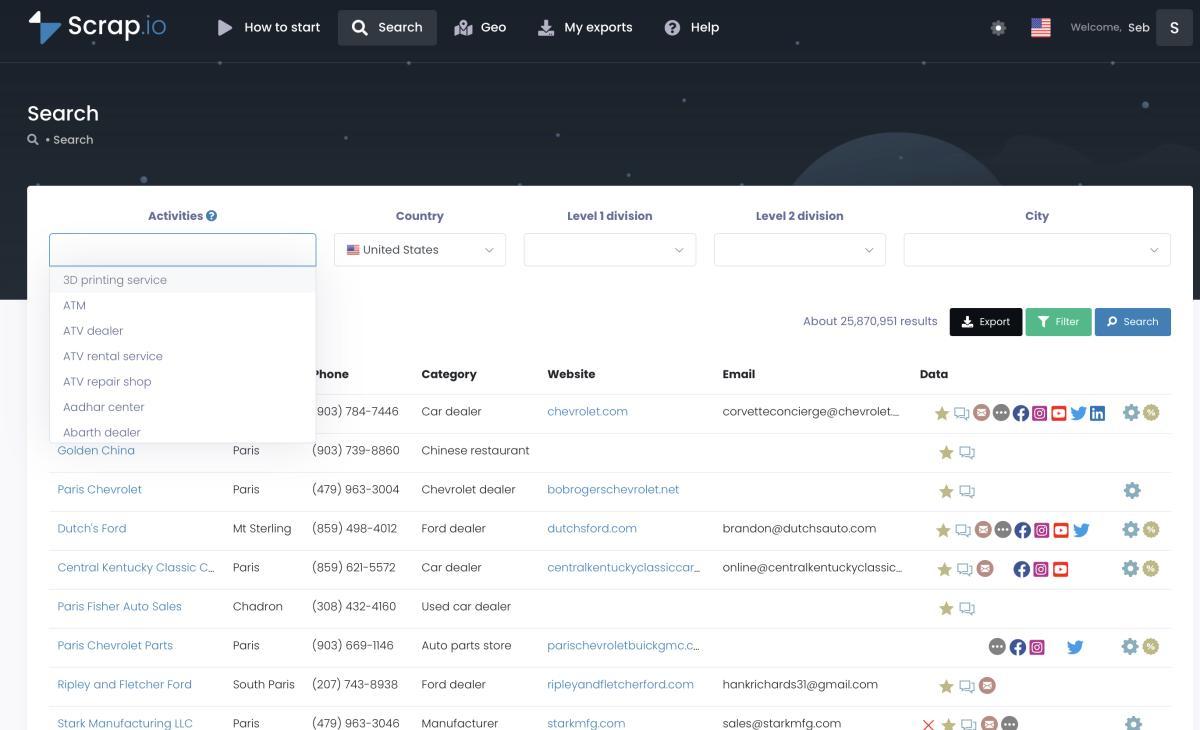
Het echte verschil zit in de filters. Je past ze toe vóór je credits uitgeeft — dus je betaalt alleen voor bruikbare contacten. Alleen bedrijven mét e-mailadres. Alleen mobiele nummers voor een sms-campagne. Alleen fiches zonder website (goud voor webbureaus). Alleen bedrijven met minder dan drie sterren die hulp kunnen gebruiken bij hun reputatie. Zero verspilling.
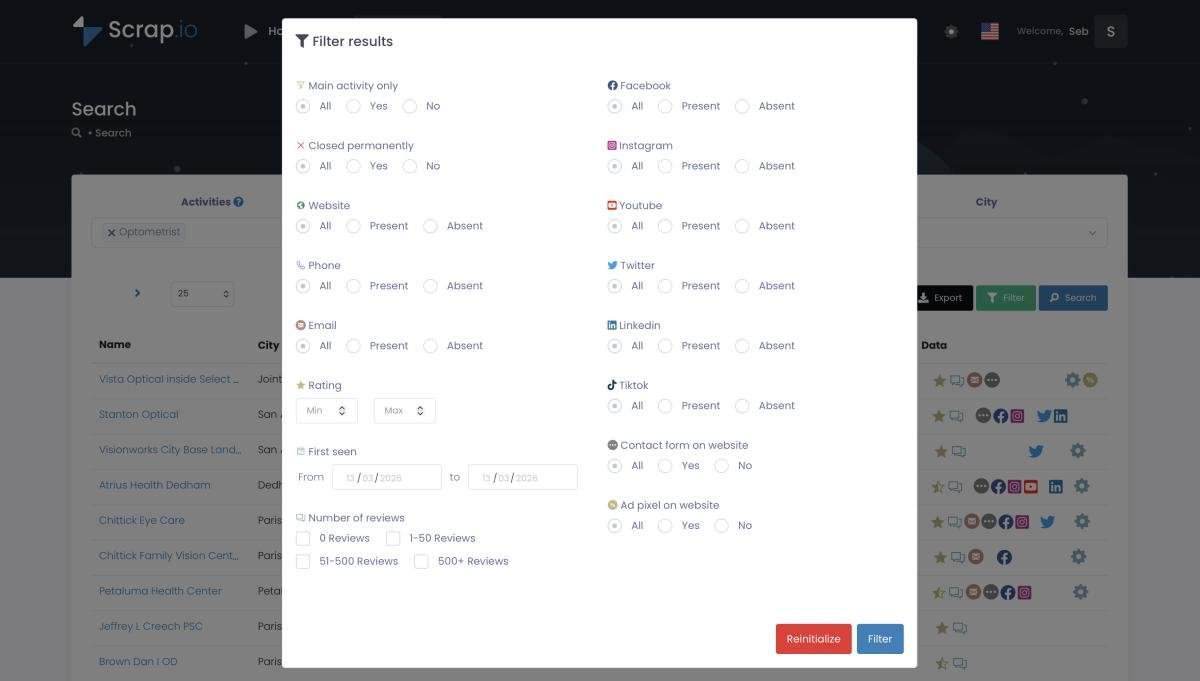
En dan is er GeoSearch, voor wie geografisch precies wil werken. Een radius rond een punt op de kaart — handig om een verzorgingsgebied af te bakenen.
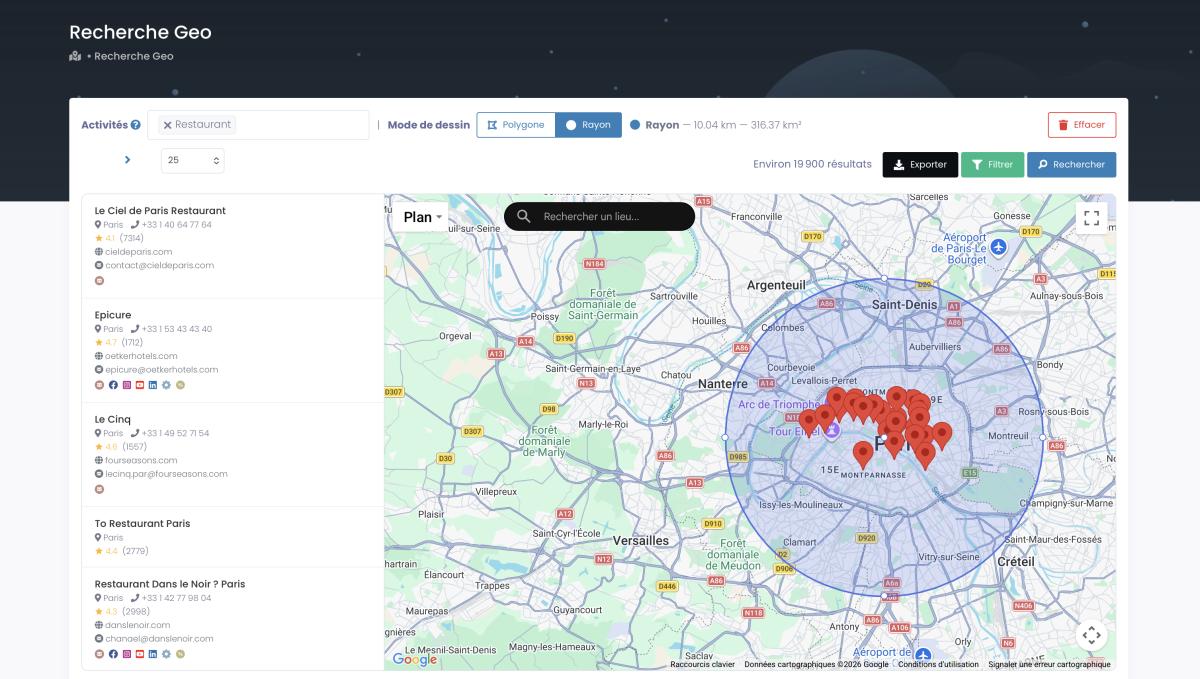
Of een polygoon die je met de hand tekent, voor een wijk of sector die niet netjes op een gemeentegrens valt.
Wil je zien hoe je begint? Deze korte video loopt de eerste stappen met je door.
Video: Scrap.io - How to Start?
50.000+ professionals gebruiken Scrap.io al. Van één stad tot een heel land in twee klikken, met filters die je credits sparen. Exporteer verse B2B-contacten direct naar CSV, Excel of je CRM. Probeer het 7 dagen gratis — 100 leads inbegrepen.
Cijfers & trends 2026
Even de harde cijfers op een rij, want ze vertellen een duidelijk verhaal.
| Statistiek | Cijfer | Bron |
|---|---|---|
| Marktomvang web scraping 2026 | $1,17 miljard (CAGR 18,5%) | The Business Research Company, 2026 |
| Verwachte marktomvang 2030 | $2,28 miljard | The Business Research Company, 2026 |
| Groei AI-scraping 2024–2029 | +$3,15 miljard (CAGR 39,4%) | Research and Markets |
| Projecten op no-code/low-code | 62% | Actowiz, 2026 |
| Minder onderhoud via AI | −85% | GroupBWT, dec. 2025 |
| US-retailers met prijsscraping | 81% (was 34% in 2020) | Actowiz / Mordor, 2025 |
| Aandeel botverkeer op het web | 10,2% | F5 Labs, 2026 |
Wat valt op? Drie dingen. De markt groeit hard, maar de AI-hoek groeit ruim twee keer zo hard. No-code is niet langer het speelgoedbroertje — het is de meerderheid geworden. En scraping is zó normaal dat ruim één op de tien webverzoeken van een bot komt. Bienvenue in 2026.
Praktijkvoorbeelden: bedrijven die het inzetten
Theorie is mooi, maar laten we naar echte cases kijken — met echte cijfers die voor zichzelf spreken.
📌 GroupBWT — 85% minder onderhoud dankzij AI
Data-engineeringbureau GroupBWT documenteerde hoe de overstap naar AI-gestuurde scraping hun onderhoudslast met 85% verlaagde. Waar hun engineers vroeger constant scripts moesten repareren zodra doelsites veranderden, herkennen de modellen nu zelf de nieuwe structuur. Minder brandjes blussen, meer tijd voor de data zelf.
📌 Outreach-agency via Google Maps — van 50 naar 400 e-mails per week
Een outreach-agency bouwde een prospectdatabase op door Google Maps-vestigingen te scrapen, zoals beschreven in de Apify-analyse van Google Maps-scrapers. Hun outreach-volume schaalde van 50 naar 400 e-mails per week — 8x meer bereik, niet door harder te werken, maar door het verzamelen te automatiseren. Dit is precies het type resultaat waar een tool als Scrap.io voor gemaakt is.
📌 Elektronica-retailer — 50.000+ SKU's gemonitord
Een elektronica-retailer zette scraping in om meer dan 50.000 SKU's bij concurrenten te volgen voor dynamische prijsstelling, gedocumenteerd in het Mordor Intelligence-marktrapport. Handmatig? Onmogelijk. Met scraping werd het een continu, geautomatiseerd proces dat de marges bewaakte zonder dat er een mens naar hoefde te kijken.
📌 Autoriteit Persoonsgegevens — de Nederlandse maatstaf
Geen bedrijfscase, maar minstens zo belangrijk. De Handreiking scraping van de Autoriteit Persoonsgegevens is de enige gezaghebbende Nederlandse bron die precies afbakent wat wél en niet mag. Wie in Nederland serieus scrapet en dit document niet heeft gelezen, neemt een onnodig risico. Lezen dus.
Veelgestelde vragen (FAQ)
Is web scraping legaal?
Ja, openbare, niet-persoonsgebonden data mag je scrapen. Let op de AVG zodra er persoonsgegevens bij komen, respecteer robots.txt en de gebruiksvoorwaarden, en houd rekening met het databankrecht (denk aan Funda). De Autoriteit Persoonsgegevens waarschuwt dat scrapen van persoonsgegevens "vrijwel nooit" is toegestaan — bedrijfsdata is veiliger terrein.
Hoe werkt web scraping?
Web scraping doorloopt vier stappen: een HTTP-verzoek naar de website, de HTML ophalen, de relevante velden parsen (via CSS-selectors of XPath), en het resultaat opslaan in een CSV, JSON of database. Kort samengevat: Verzoek → Ophalen → Parsen → Opslaan. De rest is implementatiedetail.
Wat is een web scraping tool?
Een web scraping tool automatiseert het verzamelen van webdata. Er zijn drie hoofdtypes: no-code extensies (Web Scraper, Instant Data Scraper), Python-libraries (BeautifulSoup, Scrapy, Selenium) en SaaS-platforms zoals Scrap.io, dat met een live database van Google Maps werkt in plaats van zelf te crawlen.
Kan web scraping gedetecteerd worden?
Ja. Websites herkennen scrapers aan gedrag (te snelle verzoeken), IP-reputatie en verzoek-signaturen, en kunnen blokkeren met captcha's of rate limits. Scrap.io omzeilt dat probleem door met een eigen live database te werken in plaats van sites realtime te crawlen — zo loop je niet tegen blokkades aan.
Kan ik data scrapen zonder programmeren?
Absoluut. No-code tools en SaaS-platforms zoals Scrap.io maken scraping toegankelijk voor iedereen: je zoekt, filtert en exporteert — geen code, geen installatie. Met Scrap.io haal je letterlijk in twee klikken alle vestigingen van een branche in heel Nederland op, direct exporteerbaar naar CSV of je CRM.
Wat is het verschil tussen web scraping en web crawling?
Web crawling is het systematisch doorzoeken en indexeren van pagina's — dat is wat Google doet. Web scraping is het gericht extraheren van specifieke data uit die pagina's voor analyse of hergebruik. Crawling gaat over volume en structuur; scraping over het ophalen van bruikbare, gerichte data.
Mag je Funda scrapen?
Voor commercieel gebruik: nee. Funda heeft een beschermd databankrecht op hun woningoverzicht, bevestigd door de Hoge Raad in 2002. Wil je vastgoeddata? Scrape dan de individuele makelaarssites — dat is juridisch een andere situatie, zoals de zaak-Zoekallehuizen liet zien.
Conclusie: data verzamelen als concurrentievoordeel
Web scraping is in 2026 geen specialistisch nichegebied meer. Het is een standaardinstrument voor bedrijven die data serieus nemen — voor prijsmonitoring, leadgeneratie, marktonderzoek en AI. De markt groeit richting $2,28 miljard in 2030, no-code is de meerderheid, en de AI-hoek verdubbelt het tempo.
Beheers je Python? Prima, BeautifulSoup en Scrapy zijn solide. Wil je scrapen zonder code? De no-code, API- en SaaS-opties van 2026 zijn krachtig genoeg voor professioneel werk. En wil je snel B2B-leads verzamelen in Nederland, dan is een platform dat realtime data uit Google Maps haalt de logische eerste stap — vooral omdat het je meteen in het veilige juridische segment houdt.
Juridisch: houd de AVG in de gaten, lees de Handreiking van de Autoriteit Persoonsgegevens, respecteer het databankrecht (Funda blijft het klassieke voorbeeld), en gebruik tools die compliance ingebouwd hebben. Dan zit je goed. Lars, uit de intro? Die had dit allang moeten weten.
Probeer Scrap.io 7 dagen gratis — 100 leads inbegrepen. Verse, AVG-proof B2B-contacten rechtstreeks uit Google Maps, gefilterd op jouw exacte doelgroep. 225 miljoen vestigingen, 195 landen, geen script om te onderhouden. Start je gratis proefperiode →
Generate a list of restaurant with Scrap.io
